|
My name is Duzhen Zhang, and I am a postdoctoral researcher in AI4Science at MBZUAI, where I closely collaborate with Le Song (2024.9 - now). I earned my Ph.D. in Artificial Intelligence from the Institute of Automation, Chinese Academy of Sciences (CASIA), under the supervision of Bo Xu and Tielin Zhang (2019.9 - 2024.6). Prior to that, I received my Bachelor's degree in Software Engineering from Shandong University (2015.9 - 2019.6). My past research focused on Emotion Analysis in Conversational Systems, Brain-Inspired Intelligence, and Lifelong/Continual Learning in Information Extraction. Currently, I am exploring Lifelong/Continual Learning in (Multimodal) LLMs, LLM (Coding) Agents, Lifelong Agents, Agent Memory, and Agents4BioMedicine. I am looking for cooperation. Contact me if you are interested in the above topics. Email / Google Scholar / DBLP / GitHub / Resumé |

|
|
|
- [2026.07] 🎉 One paper: MedKGent is accepted by Npj Digital Medicine. My first paper in Nature family. Keep going!
- [2026.07] 🎉 One paper: PMA is accepted by ACM MM2026.
- [2026.05] 🎉 One paper: CCDM is accepted by IEEE TPAMI.
- [2026.02] 🎉 Two papers: AutoReproduce and GlossaGen are accepted by ACL2026.
- [2025.12] 🎉 One paper: LLM Agent Survey is accepted by IEEE TPAMI.
- [2025.11] 🎉 One paper: Reasoning LLMs Survey is accepted by IEEE TPAMI.
- [2025.11] 🎉 Two papers: TinyChemVL and CCVD are accepted by AAAI2026.
- [2025.08] 🎉 One paper: Safety in LRMs is accepted by EMNLP2025. See you in Suzhou!
- [2025.07] 📣 Welcome to follow our latest survey: Context Engineering for LLMs.
- [2025.07] 🎉 One paper: SPT is accepted by IEEE TASLP.
- [2025.05] 📣 Welcome to follow our latest benchmark: LifelongAgentBench.
- [2025.05] 🎉 One paper: InfoComp is accepted by Neural Networks.
- [2025.05] 🎉 One paper: SVAD is accepted by Interspeech2025.
- [2025.05] 🎉 Three papers: BranchLoRA, ProgLoRA, and CharacterBot are accepted by ACL2025. See you in Vienna!
- [2025.04] 📣 Welcome to follow our latest survey on Safety in LRMs.
- [2025.03] 🎉 One paper: FINER is accepted by IEEE TASLP.
- [2025.02] 📣 Welcome to follow our latest survey on Reasoning LLMs.
- [2025.01] 📣 Welcome to follow our latest survey on LLM Agent.
- [2024.09] 🎉 One paper: CIDM is accepted by NeurIPS2024.
- [2024.05] 🎉 Two papers: MM-LLMs and WT&WF are accepted by ACL2024. See you in Bangkok!
- [2024.05] 🎉 One paper: PPAE is accepted by ICML2024.
- [2024.02] 📣 Stay updated on our latest review articles regarding MM-LLMs.
- [2023.10] 🎉 One paper: SPN-GA is accepted by Machine Intelligence Research (MIR).
- [2023.10] 🎉 One paper: CPFD is accepted by EMNLP2023. See you in Singapore!
- [2023.09] 🎉 One paper: ODE-RNN4RL is accepted by NeurIPS2023.
- [2023.08] 🎉 One paper: RDP is accepted by CIKM2023 (Oral).
- [2023.05] 🎉 One paper: DualGATs is accepted by ACL2023.
- [2023.04] 🎉 One paper: DLD is accepted by SIGIR2023.
- [2023.02] 🎉 One paper: FISS is accepted by CVPR2023.
- [2023.01] 🎉 One paper: SAMGN is accepted by IEEE TMM.
|
|
- Emotion Analysis in Conversational Systems: [COLING2020] , [COLING2022] , [IEEE TMM2023] , [ACL2023]
- Brain-inspired Intelligence, Spiking Neural Networks, Reinforcement Learning: [AAAI2022] , [IJCAI2022], [AAAI2023], [MIR2023], [Frontiers2025] , [NeurIPS2023]
- Lifelong/Continual Learning in Information Extraction: [CVPR2023] , [SIGIR2023] , [CIKM2023] , [EMNLP2023], [ACL2024], [IEEE TASLP2025a], [IEEE TASLP2025b]
- Lifelong/Continual Learning in (Multimodal) LLMs: [NeurIPS2024], [ACL2025a], [ACL2025b], [NN2025], [Preprint4], [AAAI2026], [IEEE TPAMI2026a], [ACM MM2026]
- LLM (Coding) Agents, Lifelong Agents, Agent Memory, Agents4BioMedicine: [IEEE TPAMI2025b], [IEEE TPAMI2025a], [EMNLP2025], [Preprint4], [Preprint5], [ACL2026a], [ACL2026b], [Npj DM2026]
- Multimodal LLMs, Multimodal Learning: [ACM MM2022] , [MIR2022], [IEEE TMM2023], [ICML2024], [ACL2024], [NeurIPS2024], [ACL2025a], [ACL2025b], [Interspeech2025], [AAAI2026a], [AAAI2026b], [IEEE TPAMI2026a], [ACM MM2026]
|
* denotes equal contribution and # denotes the corresponding author. |
|
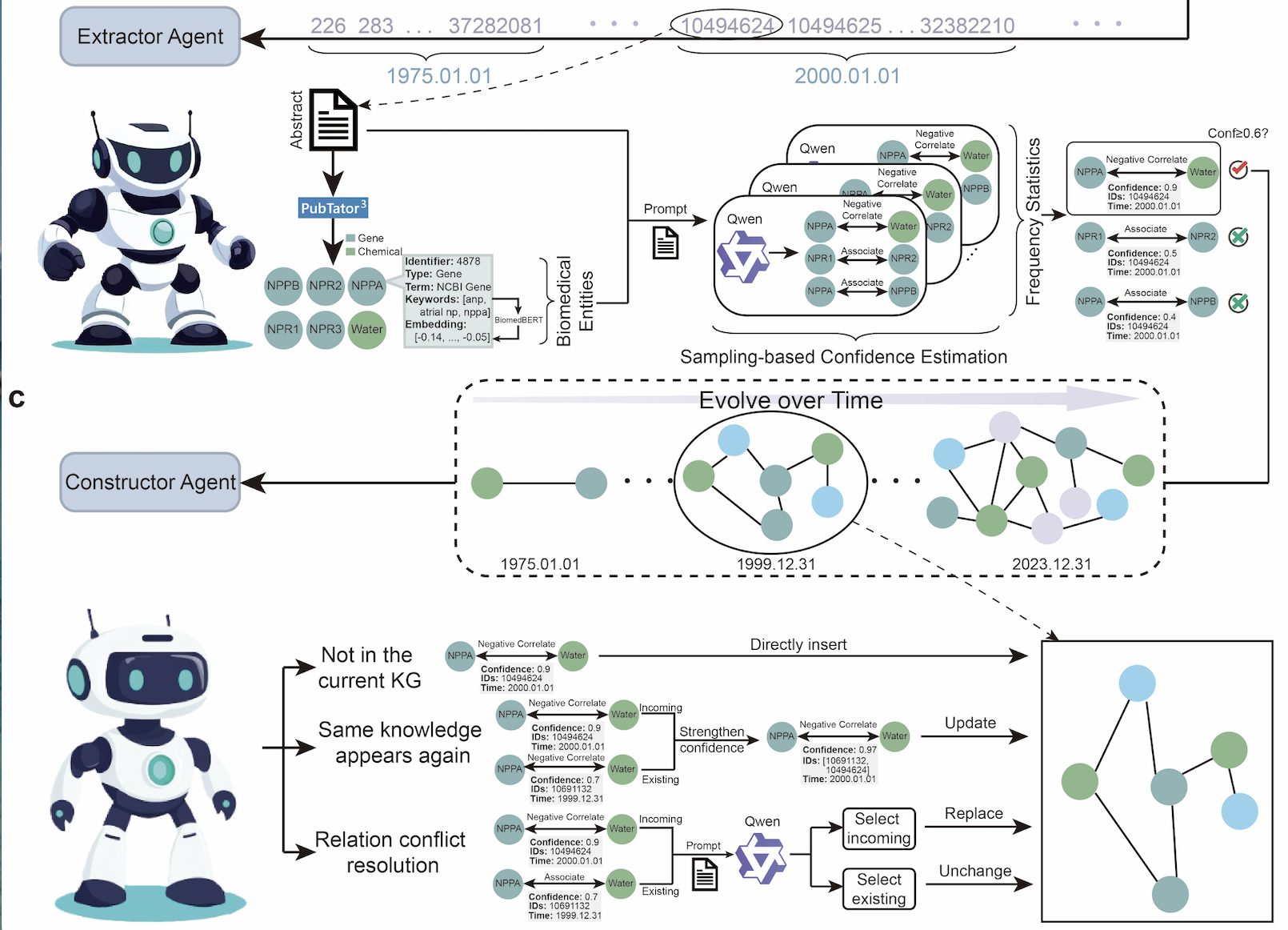
Duzhen Zhang*, Zixiao Wang*, Zhongzhi Li*, Yahan Yu, Shuncheng Jia, Jiahua Dong, Haotian Xu, Xing Wu, Yingying Zhang, Tielin Zhang, Jie Yang, Xiuying Chen#, Le Song# Npj Digital Medicine (Npj DM2026, Nature Family, IF: 18.0) Paper / Dataset / Code / DetailsThe rapid expansion of medical literature challenges the scalable structuring of domain knowledge. Knowledge Graphs (KGs) offer a solution, yet current construction methods lack generalizability and ignore the temporal dynamics of evolving knowledge. To address this, we introduce MedKGent, a Large Language Model (LLM) agent framework for building temporally evolving medical KGs. Using over 10 million PubMed abstracts from 1975 to 2023, MedKGent incrementally constructs a KG daily via two specialized agents. The Extractor Agent identifies knowledge triples and assigns confidence scores, while the Constructor Agent integrates these triples into a temporal graph, reinforcing recurring knowledge and resolving conflicts. The resulting KG contains 156,275 entities and 2,971,384 triples, making it, to our knowledge, the largest LLM-derived medical KG to date. Automated and expert assessments showed triple-validity rates approaching 90\%. In downstream evaluations, MedKGent-KG significantly improved retrieval-augmented generation for five LLMs across seven medical question-answering benchmarks. Together, these results position MedKGent as a scalable and temporally aware infrastructure for medical knowledge representation and literature-grounded AI research. |
|
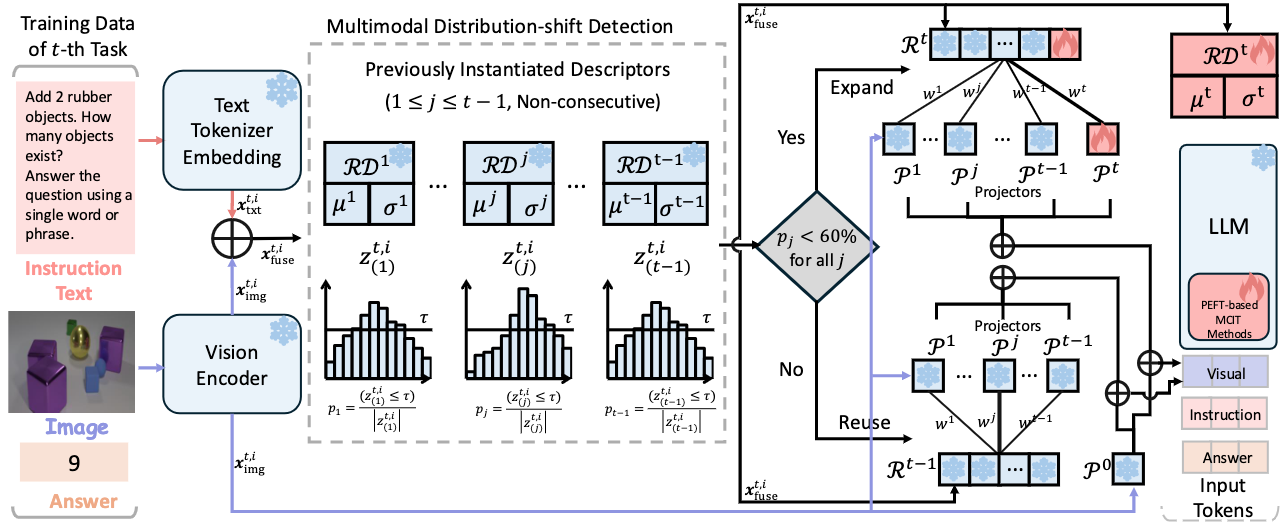
Duzhen Zhang*, Yahan Yu*, Qiaoyi Su, Jiahua Dong, Tielin Zhang# ACM International Conference on Multimedia (ACM MM2026) Paper / Code DetailsMultimodal Large Language Models (MLLMs) rely on a projector to align visual representations with the language embedding space, making it central to cross-modal understanding. In Multimodal Continual Instruction Tuning (MCIT), however, shifting visual distributions and evolving instruction semantics cause this shared projector to drift, leading to projector-level forgetting, an issue largely overlooked by methods that focus primarily on the LLM backbone. We introduce Progressive Multimodal Alignment (PMA), a framework that enables the projector to adapt continually while preserving previously learned alignment. PMA detects multimodal distribution shifts via a lightweight representation descriptor and progressively expands projector experts only when needed. An expandable router integrates expert outputs based on multimodal features, while the original pretrained projector is retained as a stable alignment anchor. This progressive mechanism balances stability and plasticity with sub-linear parameter growth and serves as a method-agnostic add-on to existing MCIT approaches. Extensive experiments on two recent MCIT benchmarks demonstrate that mitigating projector-level forgetting yields consistent gains over prior state-of-the-art methods when combined with PMA. Moreover, PMA scales across diverse MLLM backbones and model scales, demonstrating robust and broadly applicable MCIT performance. |
|
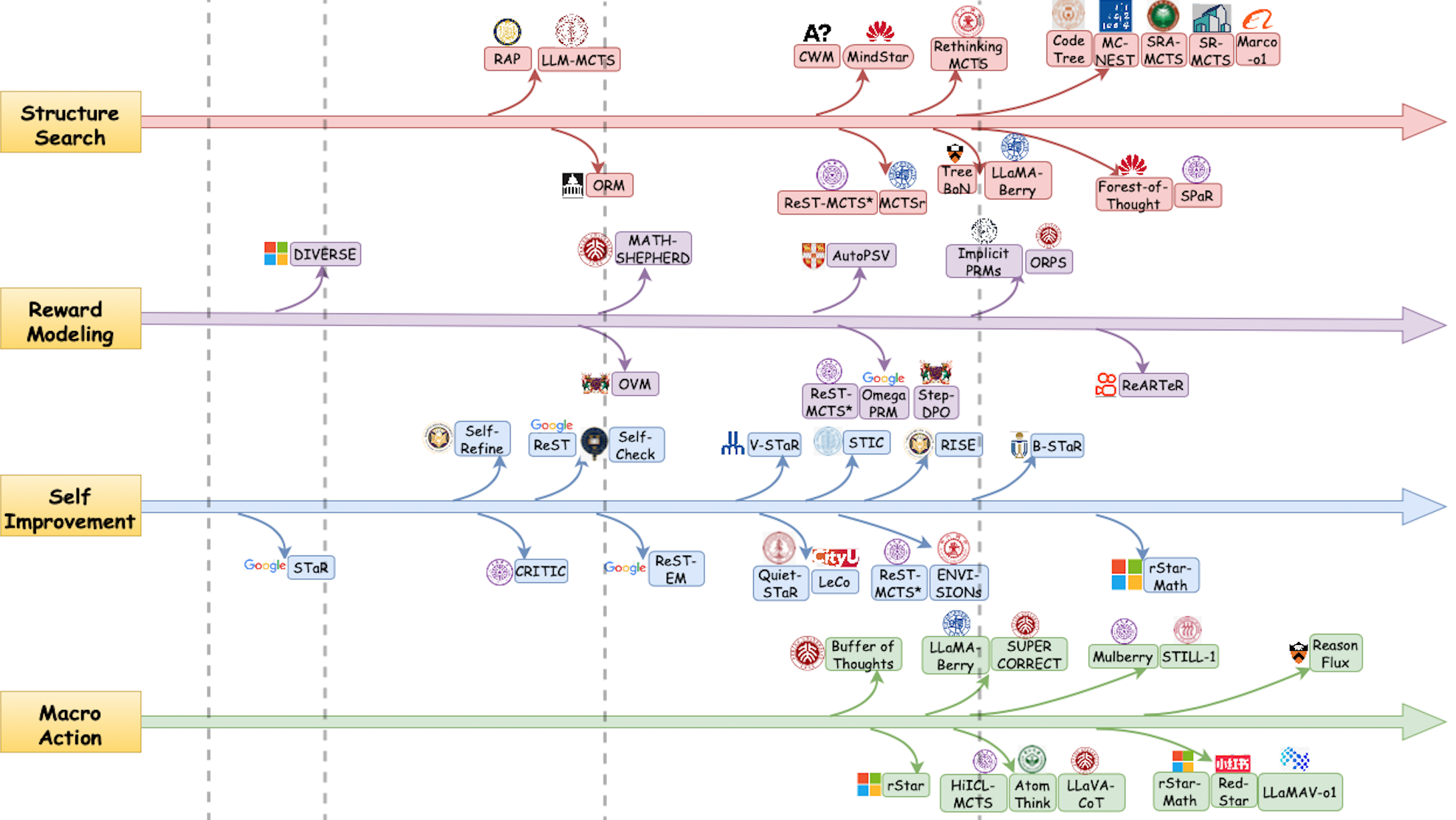
Duzhen Zhang*, Zhong-Zhi Li*, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhijiang Guo#, Le Song#, Cheng-Lin Liu# IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI2025) Paper / Code DetailsAchieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational Large Language Models (LLMs) excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI's o1/o3 and DeepSeek's R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, trace the evolution of various reasoning models, and examine the core methods that enable advanced reasoning behind them. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time GitHub Repository to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field. |
|
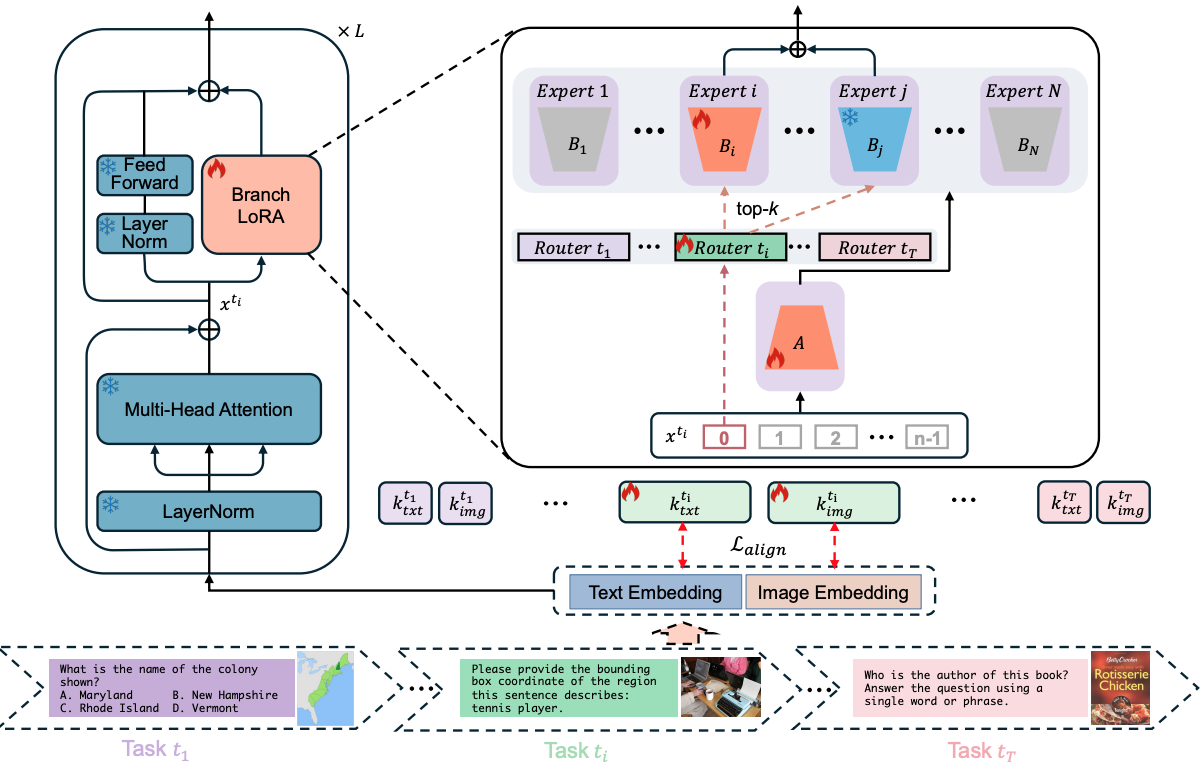
Duzhen Zhang*#, Yong Ren*, Zhong-Zhi Li, Yahan Yu, Jiahua Dong, Chenxing Li, Zhilong Ji, Jinfeng Bai ACL2025 main Paper / Code DetailsMultimodal Continual Instruction Tuning (MCIT) aims to finetune Multimodal Large Language Models (MLLMs) to continually align with human intent across sequential tasks. Existing approaches often rely on the Mixture-of-Experts (MoE) LoRA framework to preserve previous instruction alignments. However, these methods are prone to Catastrophic Forgetting (CF), as they aggregate all LoRA blocks via simple summation, which compromises performance over time. In this paper, we identify a critical parameter inefficiency in the MoELoRA framework within the MCIT context. Based on this insight, we propose BranchLoRA, an asymmetric framework to enhance both efficiency and performance. To mitigate CF, we introduce a flexible tuning-freezing mechanism within BranchLoRA, enabling branches to specialize in intra-task knowledge while fostering inter-task collaboration. Moreover, we incrementally incorporate task-specific routers to ensure an optimal branch distribution over time, rather than favoring the most recent task. To streamline inference, we introduce a task selector that automatically routes test inputs to the appropriate router without requiring task identity. Extensive experiments with the latest MCIT benchmark demonstrate that BranchLoRA significantly outperforms MoELoRA. Additionally, BranchLoRA consistently shows its superiority when scaled to different MLLM backbones and sizes. |
|
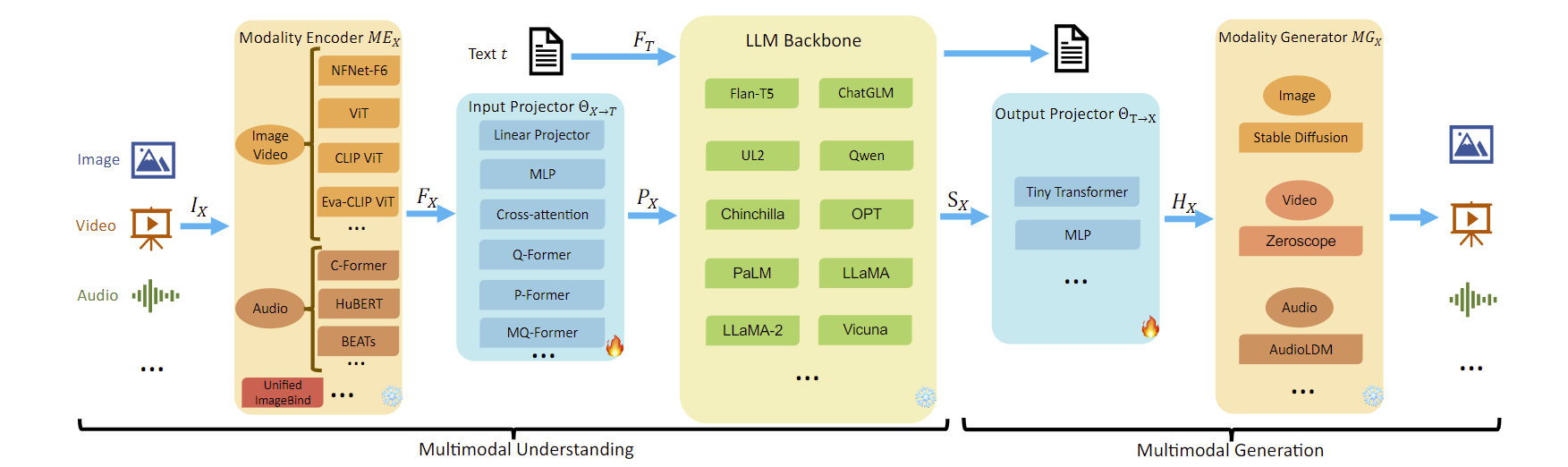
Duzhen Zhang*, Yahan Yu*, Jiahua Dong#, Chenxing Li, Dan Su, Chenhui Chu#, Dong Yu ACL2024 findings Paper / Website DetailsIn the past year, MultiModal Large Language Models (MM-LLMs) have undergone substantial advancements, augmenting off-the-shelf LLMs to support MM inputs or outputs via cost-effective training strategies. The resulting models not only preserve the inherent reasoning and decision-making capabilities of LLMs but also empower a diverse range of MM tasks. In this paper, we provide a comprehensive survey aimed at facilitating further research of MM-LLMs. Initially, we outline general design formulations for model architecture and training pipeline. Subsequently, we introduce a taxonomy encompassing 122 MM-LLMs, each characterized by its specific formulations. Furthermore, we review the performance of selected MM-LLMs on mainstream benchmarks and summarize key training recipes to enhance the potency of MM-LLMs. Finally, we explore promising directions for MM-LLMs while concurrently maintaining a real-time tracking website for the latest developments in the field. We hope that this survey contributes to the ongoing advancement of the MM-LLMs domain. |
|
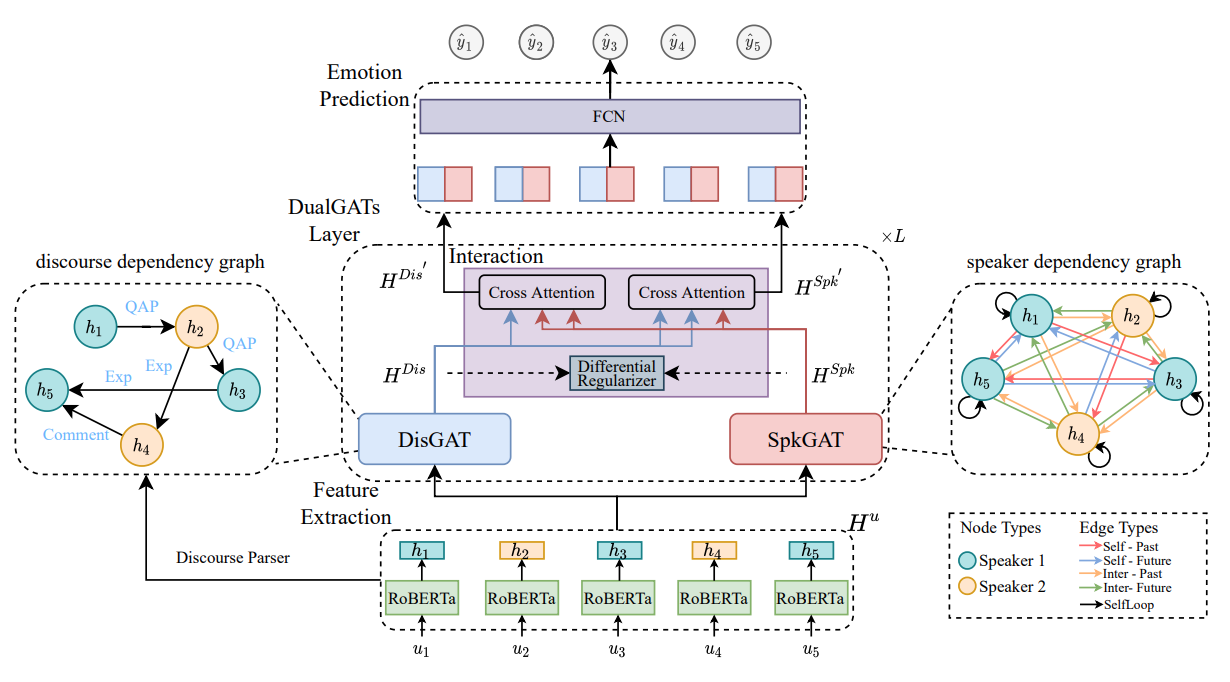
Duzhen Zhang, Feilong Chen, Xiuyi Chen# ACL2023 main Paper / Code / Poster DetailsCapturing complex contextual dependencies plays a vital role in Emotion Recognition in Conversations (ERC). Previous studies have predominantly focused on speaker-aware context modeling, overlooking the discourse structure of the conversation. In this paper, we introduce Dual Graph ATtention networks (DualGATs) to concurrently consider the complementary aspects of discourse structure and speaker-aware context, aiming for more precise ERC. Specifically, we devise a Discourse-aware GAT (DisGAT) module to incorporate discourse structural information by analyzing the discourse dependencies between utterances. Additionally, we develop a Speaker-aware GAT (SpkGAT) module to incorporate speaker-aware contextual information by considering the speaker dependencies between utterances. Furthermore, we design an interaction module that facilitates the integration of the DisGAT and SpkGAT modules, enabling the effective interchange of relevant information between the two modules. We extensively evaluate our method on four datasets, and experimental results demonstrate that our proposed DualGATs surpass state-of-the-art baselines on the majority of the datasets. |
|
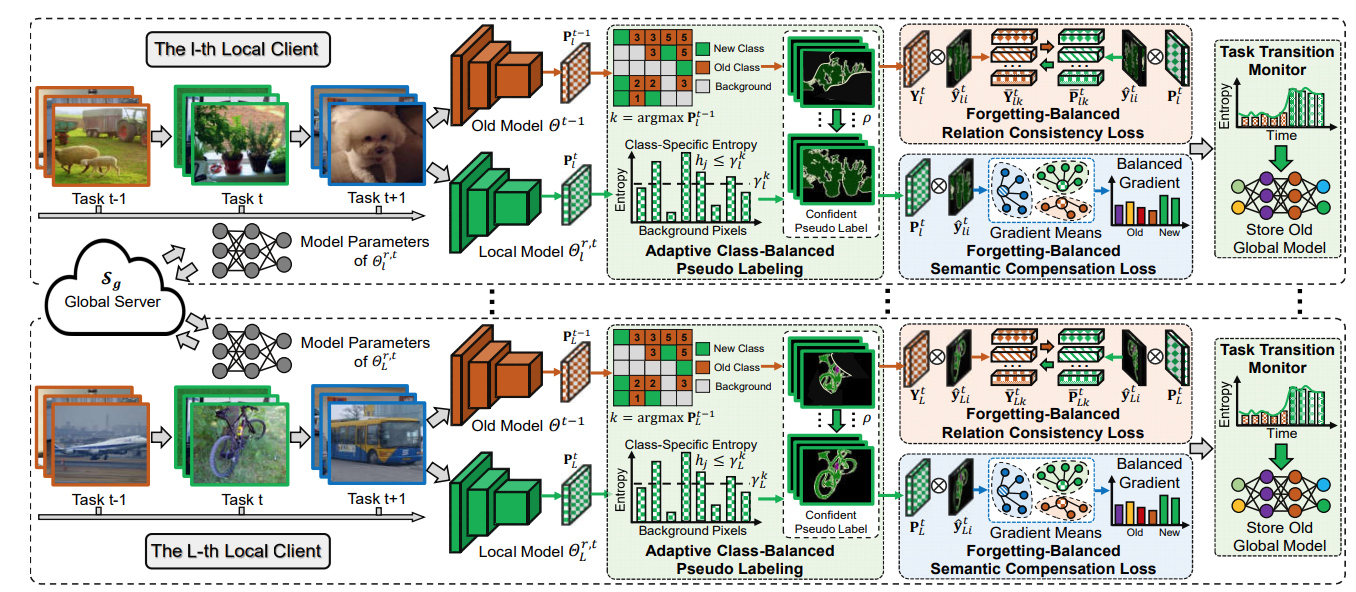
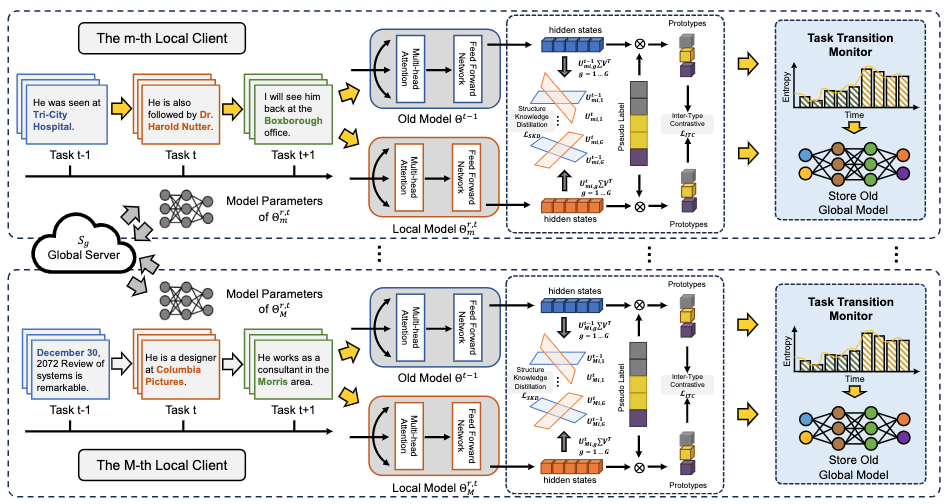
Jiahua Dong*, Duzhen Zhang*, Yang Cong#, Wei Cong, Henghui Ding, Dengxin Dai CVPR2023 Paper / Code DetailsFederated learning-based semantic segmentation (FSS) has drawn widespread attention via decentralized training on local clients. However, most FSS models assume categories are fxed in advance, thus heavily undergoing forgetting on old categories in practical applications where local clients receive new categories incrementally while have no memory storage to access old classes. Moreover, new clients collecting novel classes may join in the global training of FSS, which further exacerbates catastrophic forgetting. To surmount the above challenges, we propose a Forgetting-Balanced Learning (FBL) model to address heterogeneous forgetting on old classes from both intra-client and inter-client aspects. Specifically, under the guidance of pseudo labels generated via adaptive class-balanced pseudo labeling, we develop a forgetting-balanced semantic compensation loss and a forgetting-balanced relation consistency loss to rectify intra-client heterogeneous forgetting of old categories with background shift. It performs balanced gradient propagation and relation consistency distillation within local clients. Moreover, to tackle heterogeneous forgetting from inter-client aspect, we propose a task transition monitor. It can identify new classes under privacy protection and store the latest old global model for relation distillation. Qualitative experiments reveal large improvement of our model against comparison methods. The code is available at https://github.com/JiahuaDong/FISS. |
|
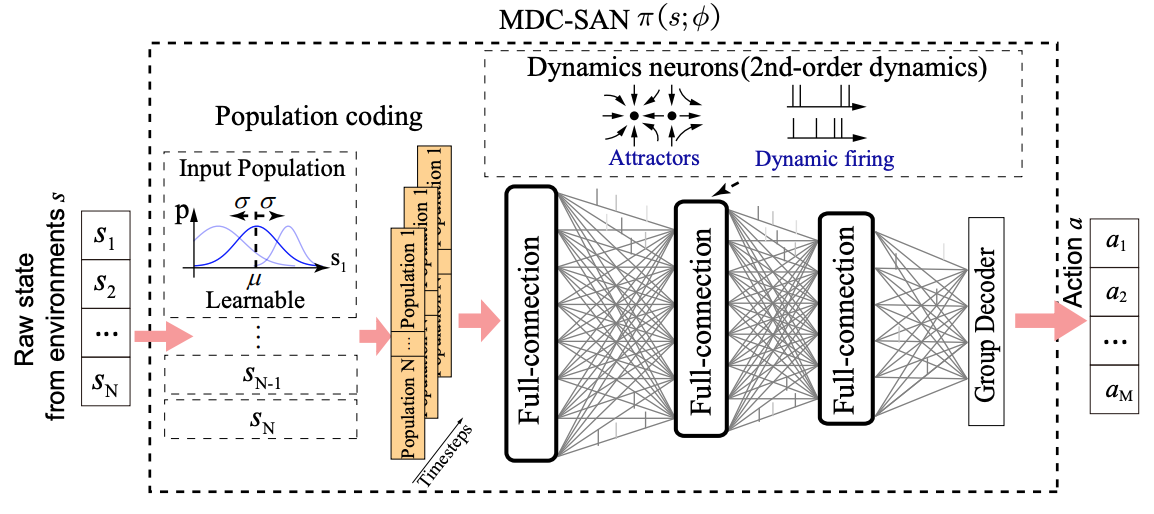
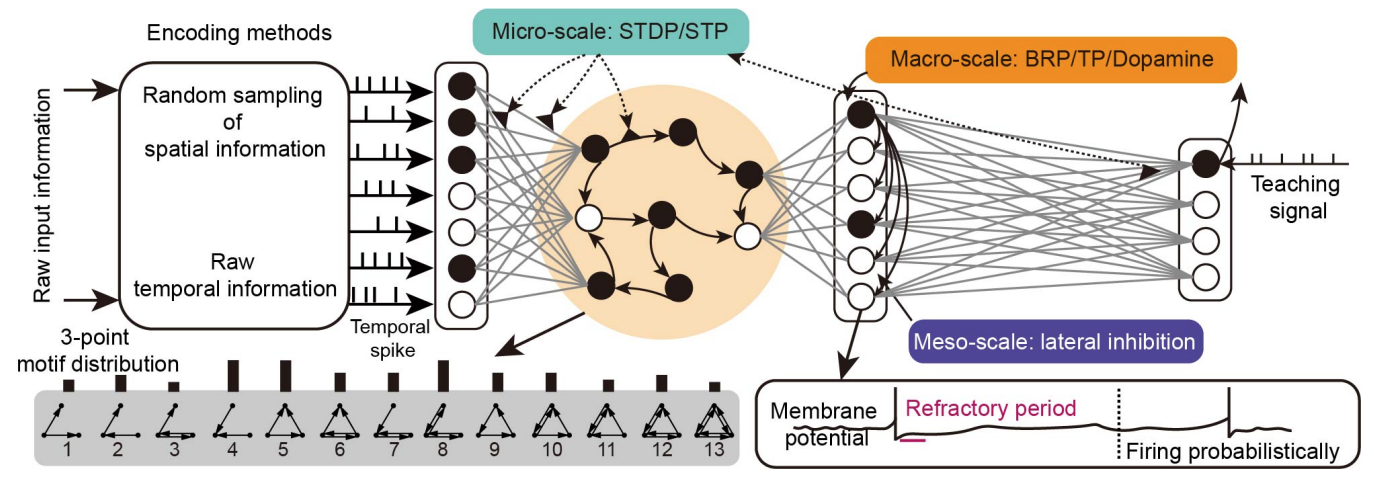
Duzhen Zhang*, Tielin Zhang*#, Shuncheng Jia, Bo Xu# AAAI2022 oral Paper DetailsWith the help of deep neural networks (DNNs), deep reinforcement learning (DRL) has achieved great success on many complex tasks, from games to robotic control. Compared to DNNs with partial brain-inspired structures and functions, spiking neural networks (SNNs) consider more biological features, including spiking neurons with complex dynamics and learning paradigms with biologically plausible plasticity principles. Inspired by the efficient computation of cell assembly in the biological brain, whereby memory-based coding is much more complex than readout, we propose a multiscale dynamic coding improved spiking actor network (MDC-SAN) for reinforcement learning to achieve effective decision-making. The population coding at the network scale is integrated with the dynamic neurons coding (containing 2nd-order neuronal dynamics) at the neuron scale towards a powerful spatial-temporal state representation. Extensive experimental results show that our MDC-SAN performs better than its counterpart deep actor network (based on DNNs) on four continuous control tasks from OpenAI gym. We think this is a significant attempt to improve SNNs from the perspective of efficient coding towards effective decision-making, just like that in biological networks. |
|
Duzhen Zhang, Shuncheng Jia, Qingyu Wang IJCAI2022 Paper DetailsIn recent years, spiking neural networks (SNNs) have received extensive attention in brain-inspired intelligence due to their rich spatially-temporal dynamics, various encoding methods, and event-driven characteristics that naturally fit the neuromorphic hardware. With the development of SNNs, brain-inspired intelligence, an emerging research field inspired by brain science achievements and aiming at artificial general intelligence, is becoming hot. This paper reviews recent advances and discusses new frontiers in SNNs from five major research topics, including essential elements (i.e., spiking neuron models, encoding methods, and topology structures), neuromorphic datasets, optimization algorithms, software, and hardware frameworks. We hope our survey can help researchers understand SNNs better and inspire new works to advance this field. |
|
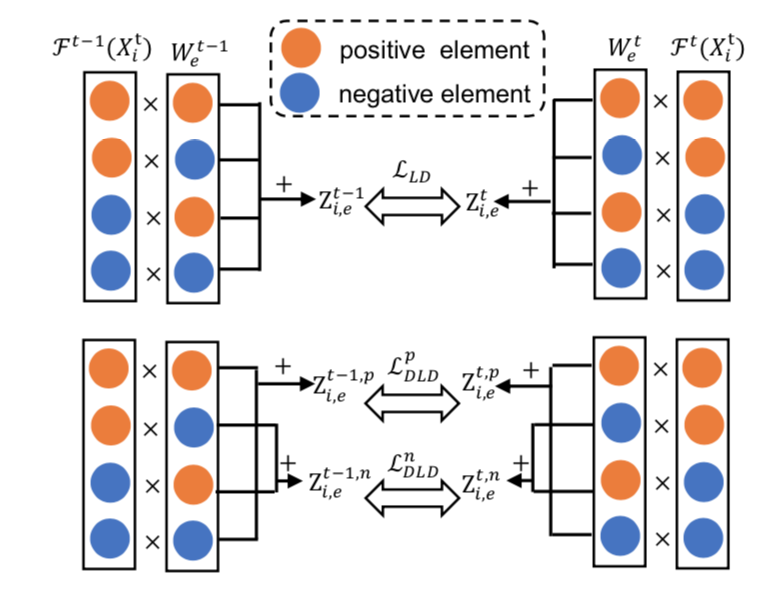
Duzhen Zhang*, Yahan Yu*, Feilong Chen, Xiuyi Chen# SIGIR2023 Paper / Poster DetailsIncremental Named Entity Recognition (INER) aims to continually train a model with new data, recognizing emerging entity types without forgetting previously learned ones. Prior INER methods have shown that Logits Distillation (LD), which involves preserving predicted logits via knowledge distillation, effectively alleviates this challenging issue. In this paper, we discover that a predicted logit can be decomposed into two terms that measure the likelihood of an input token belonging to a specific entity type or not. However, the traditional LD only preserves the sum of these two terms without considering the change in each component. To explicitly constrain each term, we propose a novel Decomposing Logits Distillation (DLD) method, enhancing the model's ability to retain old knowledge and mitigate catastrophic forgetting. Moreover, DLD is model-agnostic and easy to implement. Extensive experiments show that DLD consistently improves the performance of state-of-the-art INER methods across ten INER settings in three datasets. |
|
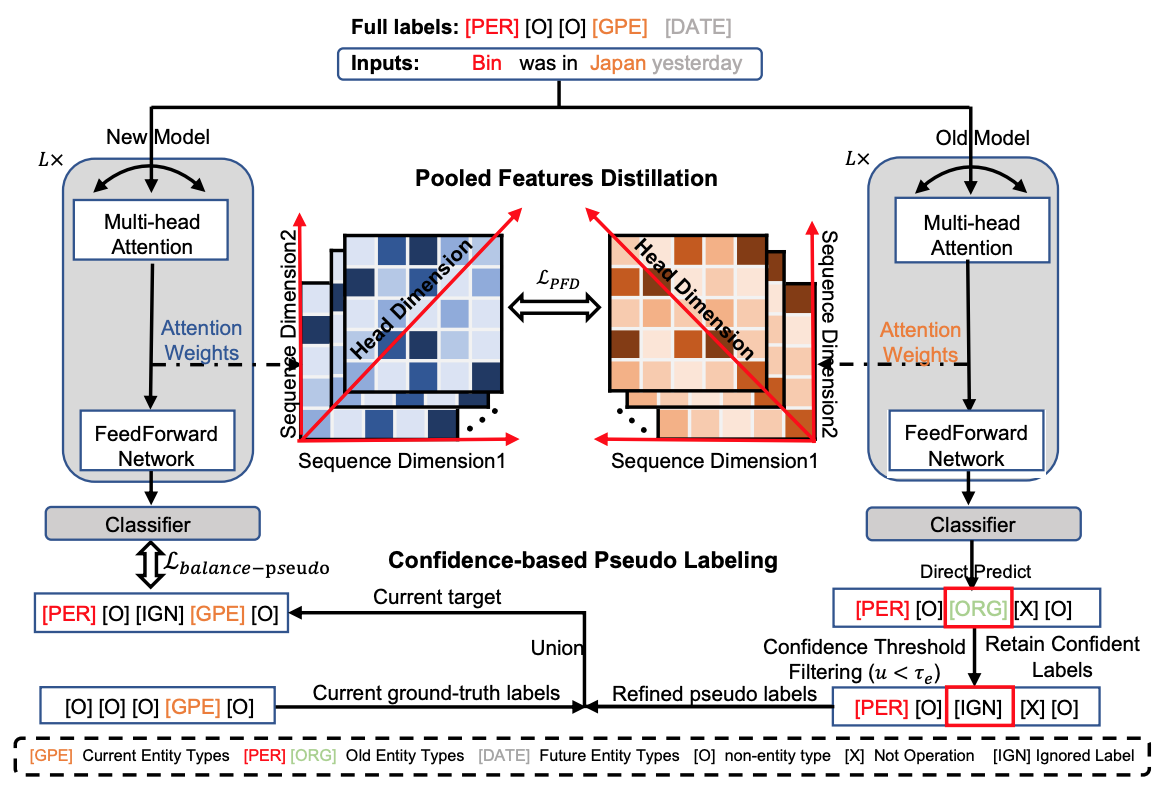
Duzhen Zhang*, Wei Cong*, Jiahua Dong#, Yahan Yu, Xiuyi Chen, Yonggang Zhang, Zhen Fang EMNLP2023 main Paper / Code / Poster / Slide DetailsContinual Named Entity Recognition (CNER) is a burgeoning area, which involves updating an existing model by incorporating new entity types sequentially. Nevertheless, continual learning approaches are often severely afflicted by catastrophic forgetting. This issue is intensified in CNER due to the consolidation of old entity types from previous steps into the non-entity type at each step, leading to what is known as the semantic shift problem of the non-entity type. In this paper, we introduce a pooled feature distillation loss that skillfully navigates the trade-off between retaining knowledge of old entity types and acquiring new ones, thereby more effectively mitigating the problem of catastrophic forgetting. Additionally, we develop a confidence-based pseudo-labeling for the non-entity type, \emph{i.e.,} predicting entity types using the old model to handle the semantic shift of the non-entity type. Following the pseudo-labeling process, we suggest an adaptive re-weighting type-balanced learning strategy to handle the issue of biased type distribution. We carried out comprehensive experiments on ten CNER settings using three different datasets. The results illustrate that our method significantly outperforms prior state-of-the-art approaches, registering an average improvement of 6.3% and 8.0% in Micro and Macro F1 scores, respectively. |
|
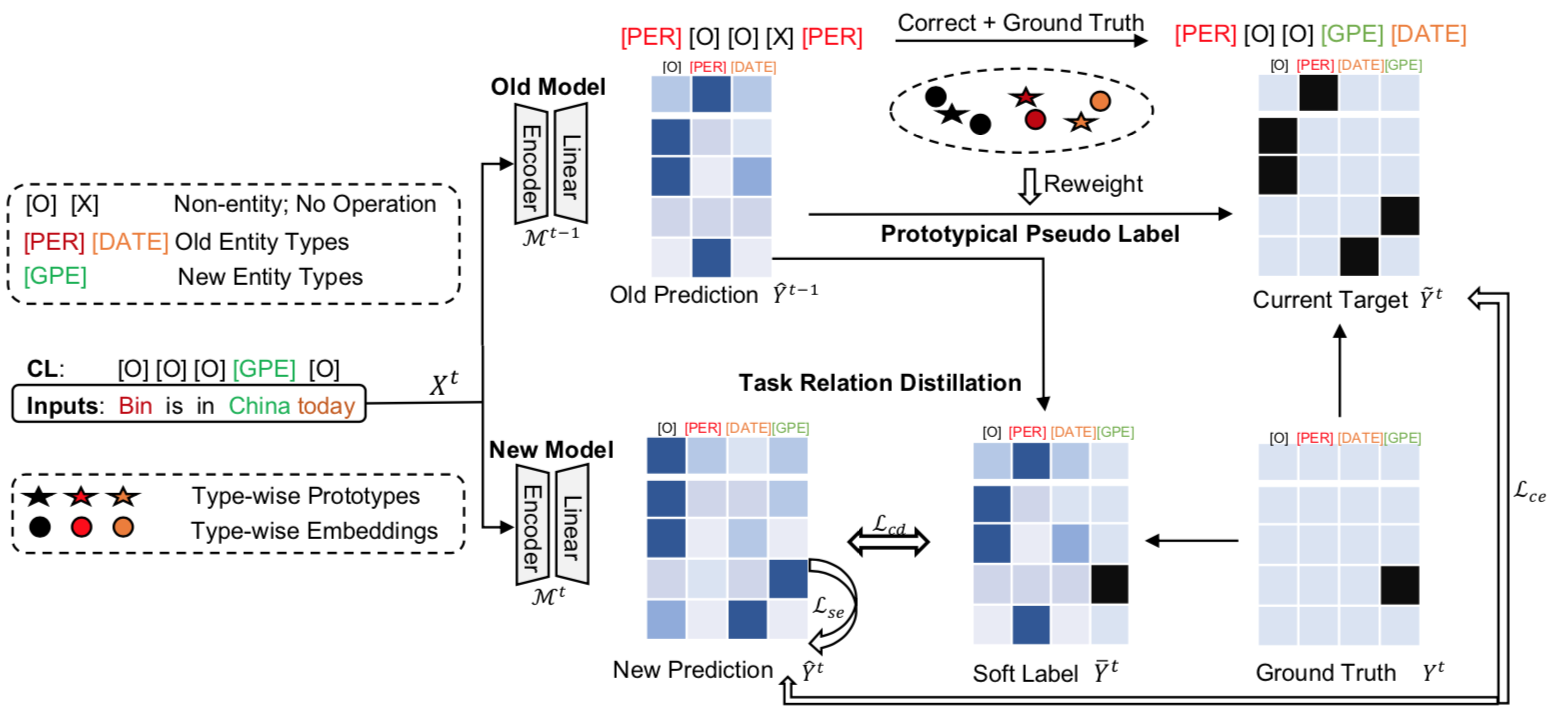
Duzhen Zhang*, Hongliu Li*, Wei Cong, Rongtao Xu, Jiahua Dong, Xiuyi Chen# CIKM2023 oral Paper / Code / Slide DetailsIncremental Named Entity Recognition (INER) involves the sequential learning of new entity types without accessing the training data of previously learned types. However, INER faces the challenge of catastrophic forgetting specific for incremental learning, further aggravated by background shift (i.e., old and future entity types are labeled as the non-entity type in the current task). To address these challenges, we propose a method called task Relation Distillation and Prototypical pseudo label (RDP) for INER. Specifically, to tackle catastrophic forgetting, we introduce a task relation distillation scheme that serves two purposes: 1) ensuring inter-task semantic consistency across different incremental learning tasks by minimizing inter-task relation distillation loss, and 2) enhancing the model's prediction confidence by minimizing intra-task self-entropy loss. Simultaneously, to mitigate background shift, we develop a prototypical pseudo label strategy that distinguishes old entity types from the current non-entity type using the old model. This strategy generates high-quality pseudo labels by measuring the distances between token embeddings and type-wise prototypes. We conducted extensive experiments on ten INER settings of three benchmark datasets (i.e., CoNLL2003, I2B2, and OntoNotes5). The results demonstrate that our method achieves significant improvements over the previous state-of-the-art methods, with an average increase of 6.08% in Micro F1 score and 7.71% in Macro F1 score. |
|
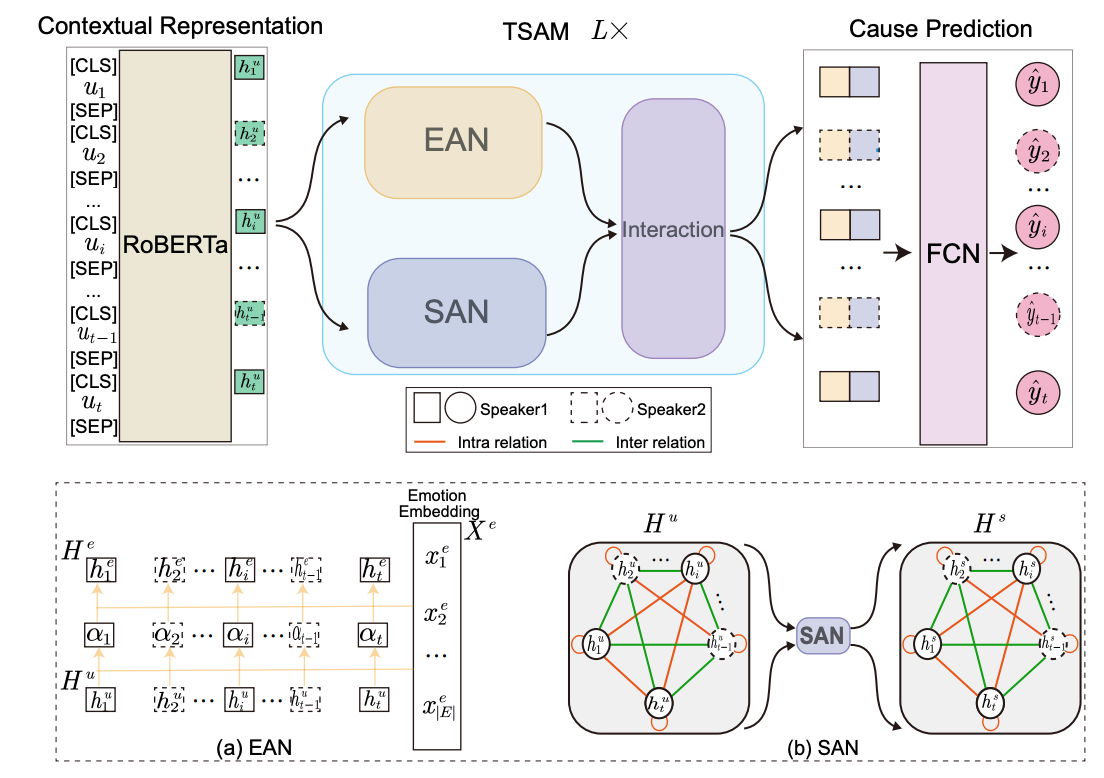
Duzhen Zhang, Zhen Yang, Fandong Meng, Xiuyi Chen#, Jie Zhou COLING2022 oral Paper / Code DetailsCausal Emotion Entailment (CEE) aims to discover the potential causes behind an emotion in a conversational utterance. Previous works formalize CEE as independent utterance pair classification problems, with emotion and speaker information neglected. From a new perspective, this paper considers CEE in a joint framework. We classify multiple utterances synchronously to capture the correlations between utterances in a global view and propose a Two-Stream Attention Model (TSAM) to effectively model the speaker’s emotional influences in the conversational history. Specifically, the TSAM comprises three modules: Emotion Attention Network (EAN), Speaker Attention Network (SAN), and interaction module. The EAN and SAN incorporate emotion and speaker information in parallel, and the subsequent interaction module effectively interchanges relevant information between the EAN and SAN via a mutual BiAffine transformation. Extensive experimental results demonstrate that our model achieves new State-Of-The-Art (SOTA) performance and outperforms baselines remarkably. |
|
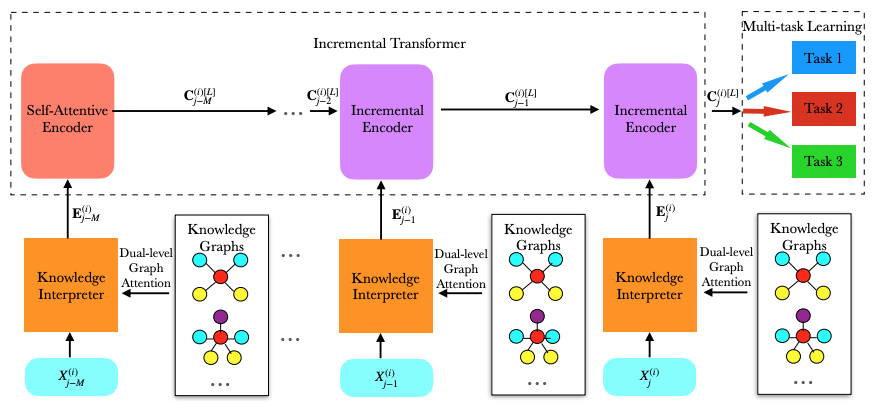
Duzhen Zhang*, Xiuyi Chen*, Shuang Xu, Bo Xu COLING2020 oral Paper DetailsEmotion recognition in textual conversations (ERTC) plays an important role in a wide range of applications, such as opinion mining, recommender systems, and so on. ERTC, however, is a challenging task. For one thing, speakers often rely on the context and commonsense knowledge to express emotions; for another, most utterances contain neutral emotion in conversations, as a result, the confusion between a few non-neutral utterances and much more neutral ones restrains the emotion recognition performance. In this paper, we propose a novel Knowledge Aware Incremental Transformer with Multi-task Learning (KAITML) to address these challenges. Firstly, we devise a dual-level graph attention mechanism to leverage commonsense knowledge, which augments the semantic information of the utterance. Then we apply the Incremental Transformer to encode multi-turn contextual utterances. Moreover, we are the first to introduce multi-task learning to alleviate the aforementioned confusion and thus further improve the emotion recognition performance. Extensive experimental results show that our KAITML model outperforms the state-of-the-art models across five benchmark datasets. |
|
Duzhen Zhang*, Yahan Yu*, Chenxing Li#, Jiahua Dong, Dong Yu IEEE Transactions on Audio, Speech, and Language Processing (TASLP2025) Paper / Code DetailsFederated Named Entity Recognition (FNER) boosts model training within each local client by aggregating the model updates of decentralized local clients, without sharing their private data. However, existing FNER methods assume fixed entity types and local clients in advance, leading to their ineffectiveness in practical applications. In a more realistic scenario, local clients receive new entity types continuously, while new local clients collecting novel data may irregularly join the global FNER training. This challenging setup, referred to here as Federated Incremental NER, renders the global model suffering from heterogeneous forgetting of old entity types from both intra-client and inter-client perspectives. To overcome these challenges, we propose a Local-Global Forgetting Defense (LGFD) model. Specifically, to address intra-client forgetting, we develop a structural knowledge distillation loss to retain the latent space's feature structure and a pseudo-label-guided inter-type contrastive loss to enhance discriminative capability over different entity types, effectively preserving previously learned knowledge within local clients. To tackle inter-client forgetting, we propose a task switching monitor that can automatically identify new entity types under privacy protection and store the latest old global model for knowledge distillation and pseudo-labeling. Experiments demonstrate significant improvement of our LGFD model over comparison methods. |
|
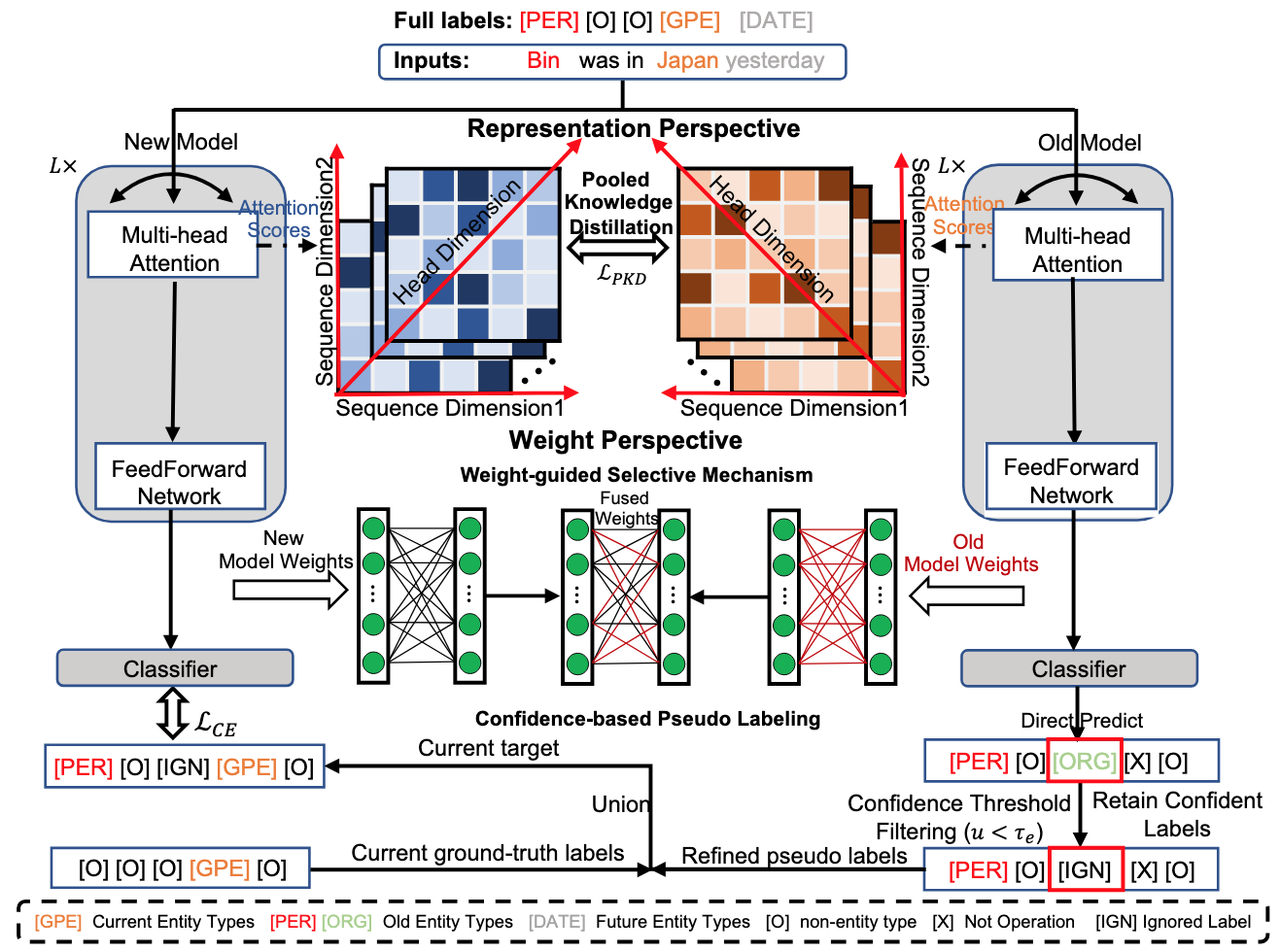
Duzhen Zhang, Chenxing Li#, Jiahua Dong, Qi Liu, Dong Yu# IEEE Transactions on Audio, Speech, and Language Processing (TASLP2025) Paper DetailsContinual Named Entity Recognition (CNER) is an evolving field that focuses on sequentially updating an existing model to incorporate new entity types. Previous CNER methods primarily utilize Knowledge Distillation (KD) to preserve prior knowledge and overcome catastrophic forgetting, strictly ensuring that the representations of old and new models remain consistent. Consequently, they often impart the model with excessive stability (i.e., retention of old knowledge) but limited plasticity (i.e., acquisition of new knowledge). To address this issue, we propose a Stability-Plasticity Trade-off (SPT) method for CNER that balances these aspects from both representation and weight perspectives. From the representation perspective, we introduce a pooling operation into the original KD, permitting a level of plasticity by consolidating representation dimensions. From the weight perspective, we dynamically merge the weights of old and new models, strengthening old knowledge while maintaining new knowledge. During this fusion, we implement a weight-guided selective mechanism to prioritize significant weights. Moreover, we develop a confidence-based pseudo-labeling approach for the current non-entity type, which predicts entity types using the old model to handle the semantic shift of the non-entity type, a challenge specific to CNER that has largely been ignored by previous methods. Extensive experiments across ten CNER settings on three benchmark datasets demonstrate that our SPT method surpasses previous CNER approaches, highlighting its effectiveness in achieving a suitable stability-plasticity trade-off. |

|
Duzhen Zhang*, Feilong Chen*, Jianlong Chang, Xiuyi Chen#, Qi Tian IEEE Transactions on Multimedia (TMM2023) Paper DetailsMulti-Modal Emotion Recognition in Conversations (MMERC) is an increasingly active research field that leverages multi-modal signals to understand the feelings behind each utterance. Modeling contextual interactions and multi-modal fusion lie at the heart of this field, with graph-based models recently being widely used for MMERC to capture global multi-modal contextual information. However, these models generally mix all modality representations in a single graph, and utterances in each modality are fully connected, potentially ignoring three problems:(1) the heterogeneity of the multi-modal context, (2) the redundancy of contextual information, and (3) over-smoothing of the graph networks. To address these problems, we propose a Structure Aware Multi-Graph Network (SAMGN) for MMERC. Specifically, we construct multiple modality-specific graphs to model the heterogeneity of the multi-modal context. Instead of fully connecting the utterances in each modality, we design a structure learning module that determines whether edges exist between the utterances. This module reduces redundancy by forcing each utterance to focus on the contextual ones that contribute to its emotion recognition, acting like a message propagating reducer to alleviate over-smoothing. Then, we develop the SAMGN via Dual-Stream Propagation (DSP), which contains two propagation streams, i.e., intra- and inter-modal, performed in parallel to aggregate the heterogeneous modality information from multi-graphs. DSP also contains a gating unit that adaptively integrates the co-occurrence information from the above two propagations for emotion recognition. Experiments on two popular MMERC datasets demonstrate that SAMGN achieves new State-Of-The-Art (SOTA) results. |
|
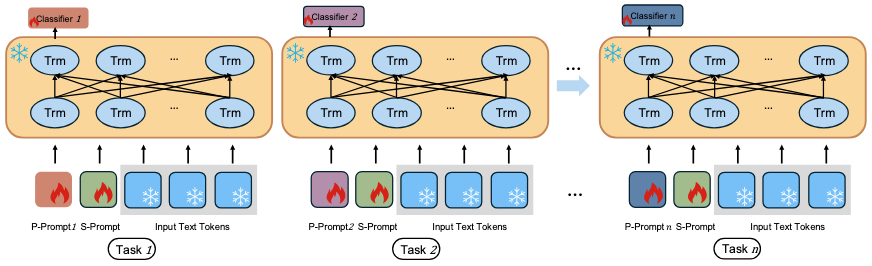
Duzhen Zhang*, Yong Ren*, Chenxing Li, Dong Yu, Tielin Zhang# Neural Networks (NN2025) Paper DetailsContinual Text Classification (CTC) aims to continuously classify new text data over time while minimizing catastrophic forgetting of previously acquired knowledge. However, existing methods often focus on task-specific knowledge, overlooking the importance of shared, task-agnostic knowledge. Inspired by the complementary learning systems theory, which posits that humans learn continually through the interaction of two systems—the hippocampus, responsible for forming distinct representations of specific experiences, and the neocortex, which extracts more general and transferable representations from past experiences—we introduce Information-Theoretic Complementary Prompts (InfoComp), a novel approach for CTC. InfoComp explicitly learns two distinct prompt spaces: P(rivate)-Prompt and S(hared)-Prompt. These respectively encode task-specific and task-invariant knowledge, enabling models to sequentially learn classification tasks without relying on data replay. To promote more informative prompt learning, InfoComp uses an information-theoretic framework that maximizes mutual information between different parameters (or encoded representations). Within this framework, we design two novel loss functions: (1) to strengthen the accumulation of task-specific knowledge in P-Prompt, effectively mitigating catastrophic forgetting, and (2) to enhance the retention of task-invariant knowledge in S-Prompt, improving forward knowledge transfer. Extensive experiments on diverse CTC benchmarks show that our approach outperforms previous state-of-the-art methods. |
|
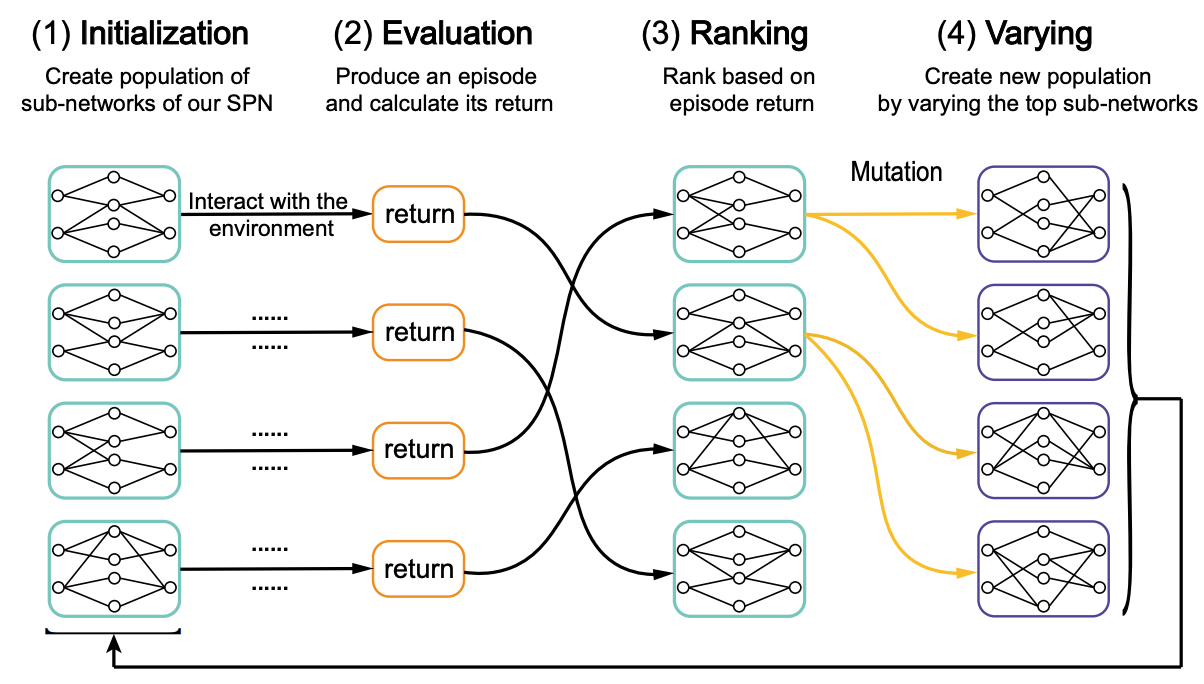
Duzhen Zhang, Tielin Zhang#, Shuncheng Jia, Qingyu Wang, Bo Xu# Machine Intelligence Research (MIR2023) Paper / Code DetailsLearning from the interaction is the primary way biological agents know about the environment and themselves. Modern deep reinforcement learning (DRL) explores a computational approach to learning from interaction and has significantly progressed in solving various tasks. However, the powerful DRL is still far from biological agents in energy efficiency. Although the underlying mechanisms are not fully understood, we believe that the integration of spiking communication between neurons and biologically-plausible synaptic plasticity plays a prominent role. Following this biological intuition, we optimize a spiking policy network (SPN) by a genetic algorithm as an energy-efficient alternative to DRL. Our SPN mimics the sensorimotor neuron pathway of insects and communicates through event-based spikes. Inspired by biological research that the brain forms memories by forming new synaptic connections and rewires these connections based on new experiences, we tune the synaptic connections instead of weights in SPN to solve given tasks. Experimental results on several robotic control tasks show that our method can achieve the performance level of mainstream DRL methods and exhibit significantly higher energy efficiency. |

|
Feilong Chen*, Duzhen Zhang*, Minglun Han*, Xiuyi Chen, Jing Shi, Shuang Xu, Bo Xu Machine Intelligence Research (MIR2022) Paper / Code DetailsIn the past few years, the emergence of pre-training models has brought uni-modal fields such as computer vision (CV) and natural language processing (NLP) to a new era. Substantial works have shown that they are beneficial for downstream uni-modal tasks and avoid training a new model from scratch. So can such pre-trained models be applied to multi-modal tasks? Researchers have explored this problem and made significant progress. This paper surveys recent advances and new frontiers in vision-language pre-training (VLP), including image-text and video-text pre-training. To give readers a better overall grasp of VLP, we first review its recent advances in five aspects: feature extraction, model architecture, pre-training objectives, pre-training datasets, and downstream tasks. Then, we summarize the specific VLP models in detail. Finally, we discuss the new frontiers in VLP. To the best of our knowledge, this is the first survey focused on VLP. We hope that this survey can shed light on future research in the VLP field. |
|
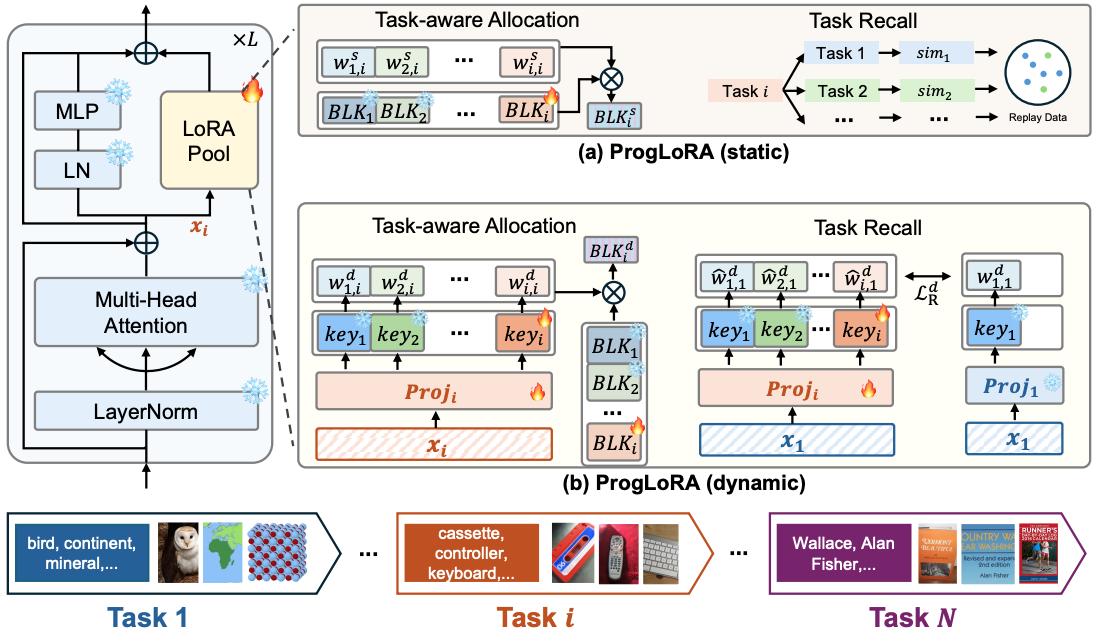
Yahan Yu, Duzhen Zhang#, Yong Ren, Xuanle Zhao, Xiuyi Chen, Chenhui Chu ACL2025 findings Paper / Code DetailsMultimodal Continual Instruction Tuning (MCIT) empowers Multimodal Large Language Models (MLLMs) to adapt to ever-evolving requirements without continuous costly retraining. However, MCIT faces challenges in mitigating Catastrophic Forgetting (CF) and enhancing Knowledge Transfer (KT). Existing works combine Mixture-of-Expert (MoE) and LoRA to address these. However, using a fixed number of shared LoRA blocks across tasks can lead to the overwriting of acquired knowledge, making MLLMs harder to handle CF and KT. Therefore, we propose the Progressive LoRA framework (ProgLoRA), which contains a progressive LoRA pool and trains a new LoRA block for each incremental task to reduce knowledge interference. Specifically, ProgLoRA has two key mechanisms: task-aware allocation for effectively leveraging acquired knowledge at current task and task recall for realigning the model with learned tasks. Additionally, considering different application scenarios, we design a static ProgLoRA for the more idealized basic setting and a dynamic ProgLoRA for the more realistic challenging setting. Experiments on the latest MCIT benchmark demonstrate that ProgLoRA outperforms existing approaches. |
|
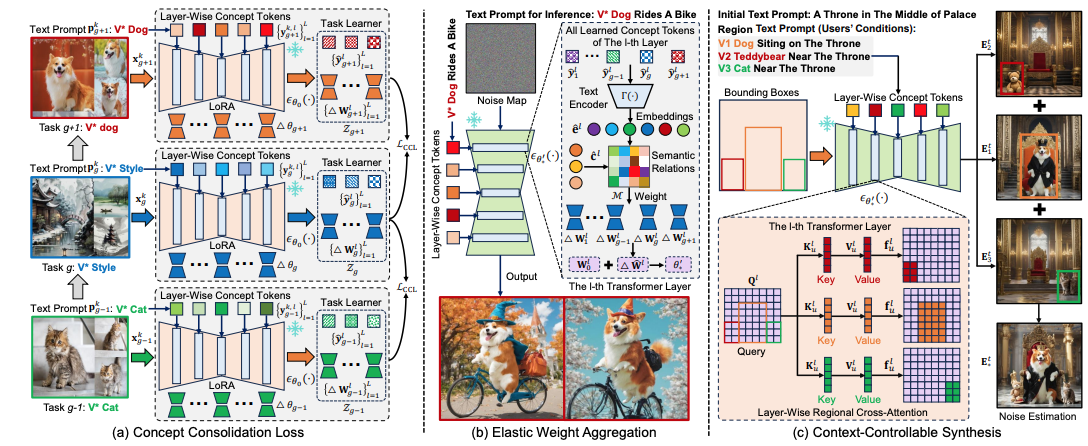
Jiahua Dong*, Wenqi Liang*, Hongliu Li#, Duzhen Zhang#, Meng Cao, Henghui Ding, Salman Khan, Fahad Khan NeurIPS2024 Paper / Code DetailsCustom diffusion models (CDMs) have attracted widespread attention due to their astonishing generative ability for personalized concepts. However, most existing CMDs unreasonably assume that personalized concepts are fixed and cannot change over time. Moreover, they heavily suffer from catastrophic forgetting and concept neglect on old personalized concepts when continually learning a series of new concepts. To address these challenges, we propose a novel Concept-Incremental text-to-image Diffusion Model (CIDM), which can resolve catastrophic forgetting and concept neglect to learn new customization tasks in a concept-incremental manner. Specifically, to surmount the catastrophic forgetting of old concepts, we develop a concept consolidation loss and an elastic weight aggregation module. They can explore task-specific and task-shared knowledge during training, and aggregate all low-rank weights of old concepts based on their contributions during inference. Moreover, in order to address concept neglect, we devise a context-controllable synthesis strategy that leverages expressive regional features and noise estimation to control the contexts of generated images according to user conditions. Experiments verify that our CIDM surpasses existing custom diffusion models. |
|
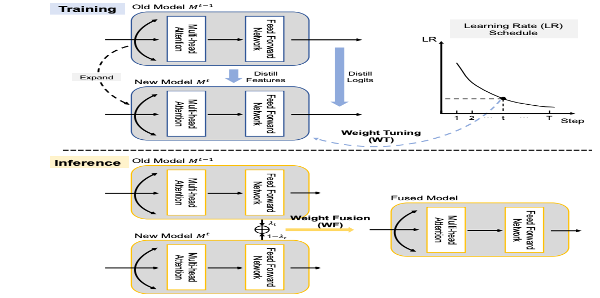
Yahan Yu, Duzhen Zhang#, Xiuyi Chen, Chenhui Chu ACL2024 findings Paper / Code DetailsContinual Named Entity Recognition (CNER) is dedicated to sequentially learning new entity types while mitigating catastrophic forgetting of old entity types. Traditional CNER approaches commonly employ knowledge distillation to retain old knowledge within the current model. However, because only the representations of old and new models are constrained to be consistent, the reliance solely on distillation in existing methods still suffers from catastrophic forgetting. To further alleviate the forgetting issue of old entity types, this paper introduces flexible Weight Tuning (WT) and Weight Fusion (WF) strategies for CNER. The WT strategy, applied at each training step, employs a learning rate schedule on the parameters of the current model. After learning the current task, the WF strategy dynamically integrates knowledge from both the current and previous models for inference. Notably, these two strategies are model-agnostic and seamlessly integrate with existing State-Of-The-Art (SOTA) models. Extensive experiments demonstrate that the WT and WF strategies consistently enhance the performance of previous SOTA methods across ten CNER settings in three datasets. |
|
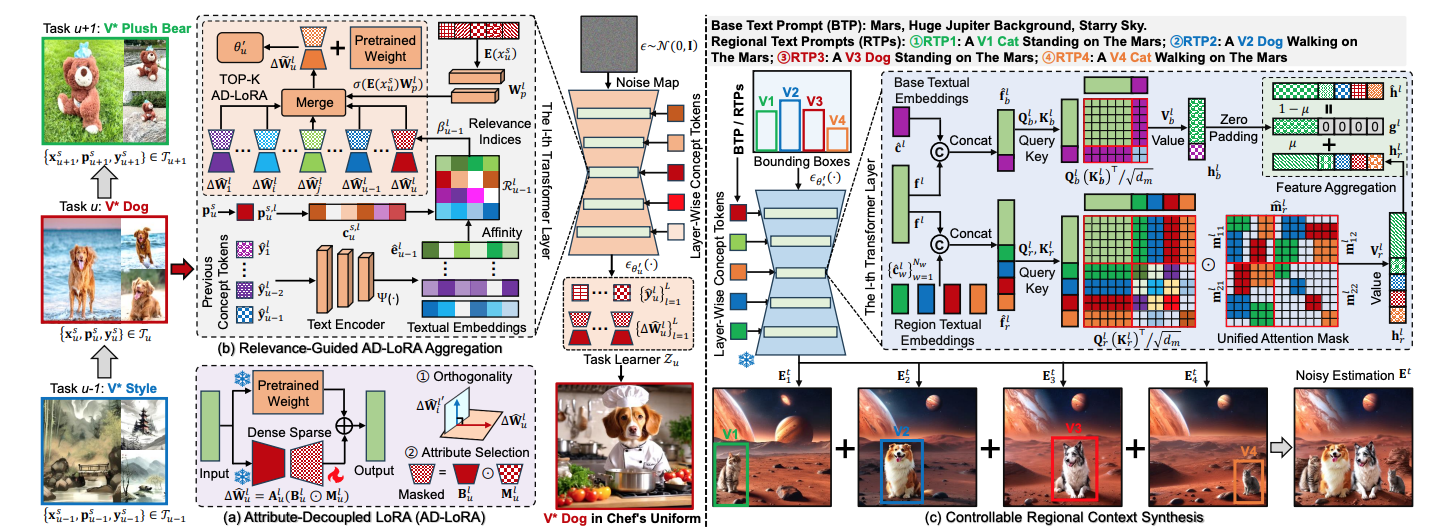
Jiahua Dong*, Wenqi Liang*, Hongliu Li, Yang Cong#, Duzhen Zhang, Hanbin Zhao, Henghui Ding, Yulun Zhang, Salman Khan, Fahad Shahbaz Khan IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI2026) Paper DetailsCustom diffusion models (CDMs) have garnered significant interest owing to their remarkable capacity for generating personalized concepts. However, the majority of CDMs unrealistically presume that the user’s collection of personalized concepts is static and incapable of incremental growth over time. Furthermore, they exhibit significant catastrophic forgetting and concept neglect of previously learned concepts when incrementally learning a sequence of new ones. To resolve the above challenges, we develop a novel Continually Customizable Diffusion Model (CCDM), enabling users to perform concept-incremental versatile customization. Specifically, we design an attribute-decoupled LoRA (AD-LoRA) module and a relevance-guided AD-LoRA aggregation strategy to mitigate catastrophic forgetting. They can preserve concept-specific attributes of each task and leverage beneficial inter-task correlations to enhance the continual learning of new customization tasks. Additionally, to address the challenge of concept neglect, we propose a controllable regional context synthesis strategy that performs multi-concept composition in alignment with user-provided conditions. This strategy enhances the overall consistency in multi-concept synthesis by guaranteeing semantic independence between user-defined regions and their smooth boundary transitions. Experiments show our CCDM exhibits significant improvements over baseline methods. |
|
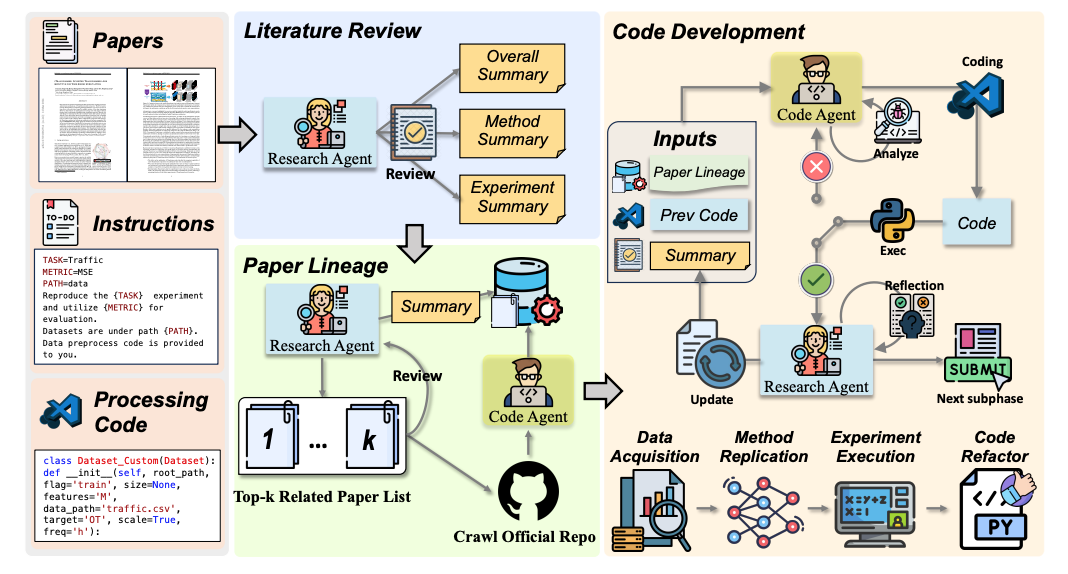
Xuanle Zhao, Zilin Sang, Yuxuan Li, Qi Shi, Weilun Zhao, Shuo Wang, Duzhen Zhang, Xu Han, Zhiyuan Liu, Maosong Sun ACL2026 main Paper / Code DetailsEfficient experiment reproduction is critical to accelerating progress in artificial intelligence. However, the inherent complexity of method design and training procedures presents substantial challenges for automation. Notably, reproducing experiments often requires implicit domain-specific knowledge not explicitly documented in the original papers. To address this, we introduce the paper lineage algorithm, which identifies and extracts implicit knowledge from the relevant references cited by the target paper. Building on this idea, we propose AutoReproduce, a multi-agent framework capable of automatically reproducing experiments described in research papers in an end-to-end manner. AutoReproduce enhances code executability by generating unit tests alongside the reproduction process. To evaluate the reproduction capability, we construct ReproduceBench, a benchmark annotated with verified implementations, and introduce novel evaluation metrics to assess both the reproduction and execution fidelity. Experimental results demonstrate that AutoReproduce outperforms the existing strong agent baselines on all five evaluation metrics by a peak margin of over 70%. In particular, compared to the official implementations, AutoReproduce achieves an average performance gap of 22.1% on 89.74% of the executable experiment runs. |
|
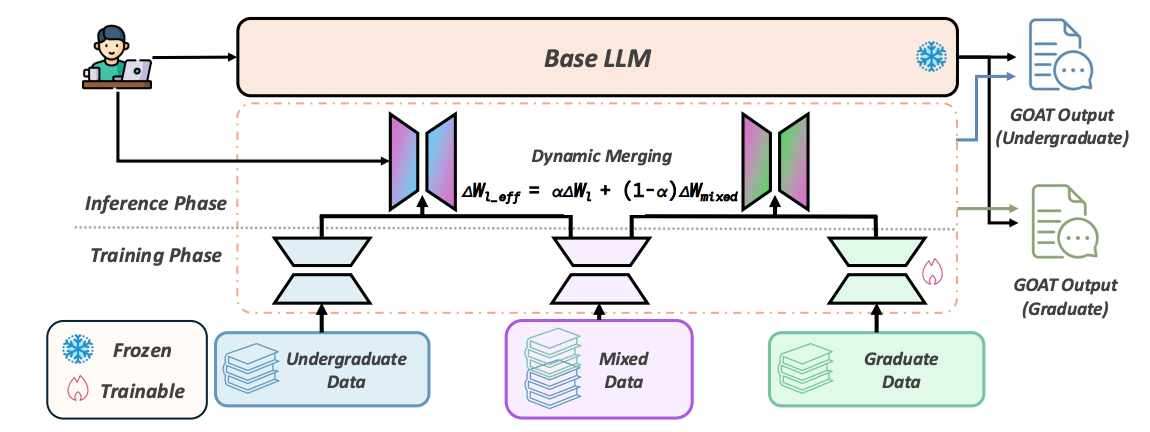
Zixiao Wang, Duzhen Zhang, Juntian Zhang, Yuhan Liu, Guoming Li, Haolun Wu, Le Song, Xiuying Chen ACL2026 findings Paper / Code DetailsWhen reading foreign-language literature, non-native users often face significant challenges. Existing traditional machine translation systems tend to obscure or mistranslate key terminology, while paraphrasing aimed at lay readers often oversimplifies it, thereby hindering their ability to master domain-specific technical vocabulary. To bridge this gap, we first define a novel task, Glossing-Oriented Academic Translation (GOAT), which aims to produce translations dynamically adapted to a reader's academic proficiency, or level. We then propose GlossaGen, a comprehensive framework to address this task. GlossaGen features two key innovations: a multi-agent data synthesis pipeline that leverages academic personas to automatically generate a large-scale, structured dataset with level-specific explanations; and a novel training strategy based on dynamic adapter merging, which balances task generalization with user-level specialization by combining a ''generalist'' adapter with a fine-grained ''expert'' one. We evaluate GlossaGen on our synthesized benchmark, where results from automatic metrics, large language model (LLM)-based assessments, and human evaluations consistently demonstrate that our approach achieves higher scores than strong baselines across most metrics. Our framework provides a scalable pathway to enhance the comprehensibility of scientific literature for non-native readers, delivering more accurate translations accompanied by pedagogically sound, level-specific term explanations, and we release our code and data to facilitate further research. |
|
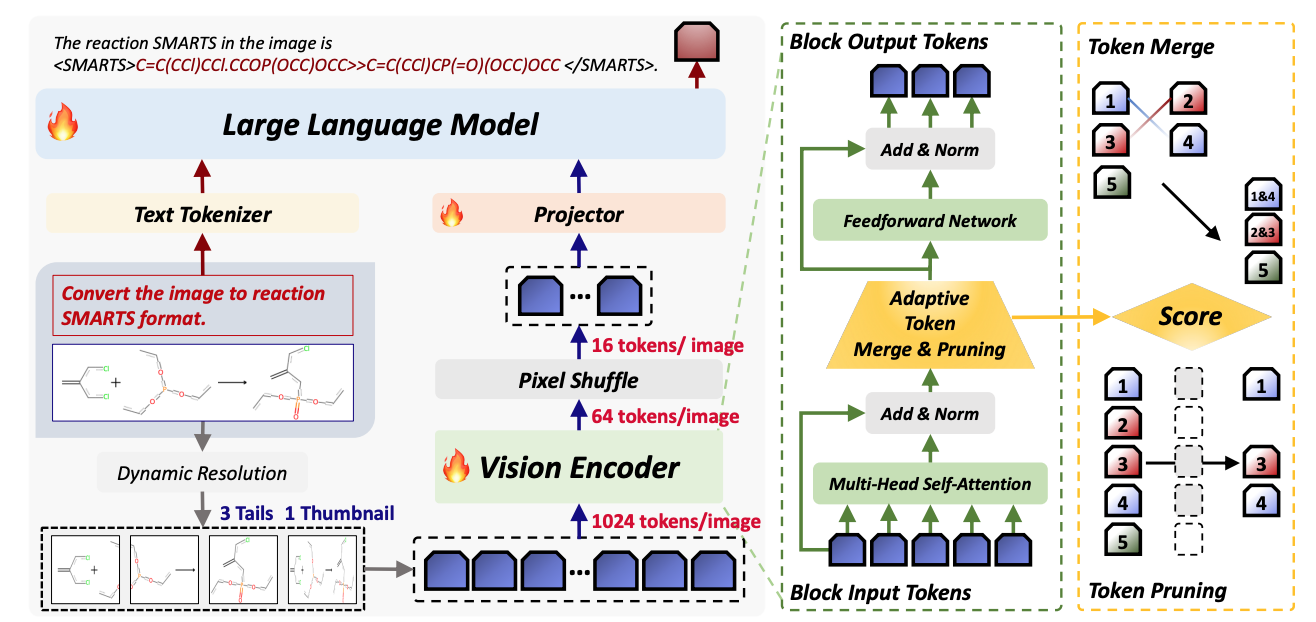
Xuanle Zhao, Shuxin Zeng, Xinyuan Cai, Xiang Cheng, Duzhen Zhang, Xiuyi Chen, Bo Xu AAAI2026 Paper / Code DetailsWhile Vision Language Models (VLMs) have demonstrated remarkable capabilities in general visual understanding, their application in the chemical domain has been limited, with previous works predominantly focusing on text and thus ignoring critical visual information like molecular structures. Current approaches that directly adopt standard VLMs for chemical tasks suffer from two primary issues: (i) computational inefficiency of processing entire chemical images with non-informative backgrounds. (ii) narrow scope on molecular-level tasks that restricts progress in chemical reasoning. In this work, we propose TinyChemVL, an efficient and powerful chemical VLM that leverages visual token reduction and reaction-level tasks to improve model efficiency and reasoning capacity. Furthermore, we propose ChemVR, a reaction-level benchmark for assessing vision-based reaction recognition and prediction tasks. Directly predicting reaction products from molecular images poses a non-trivial challenge, requiring models to integrate recognition and reasoning capacities. Our results demonstrate that with only 4B parameters, TinyChemVL achieves superior performance on both molecular and reaction tasks, while also demonstrating faster inference and training speeds compared to existing models. Notably, TinyChemVL outperforms ChemVLM while utilizing only 1/16th of the visual tokens. This work highlights a path toward building efficient yet powerful VLMs for chemical domains by co-designing model architecture and task complexity. |
|
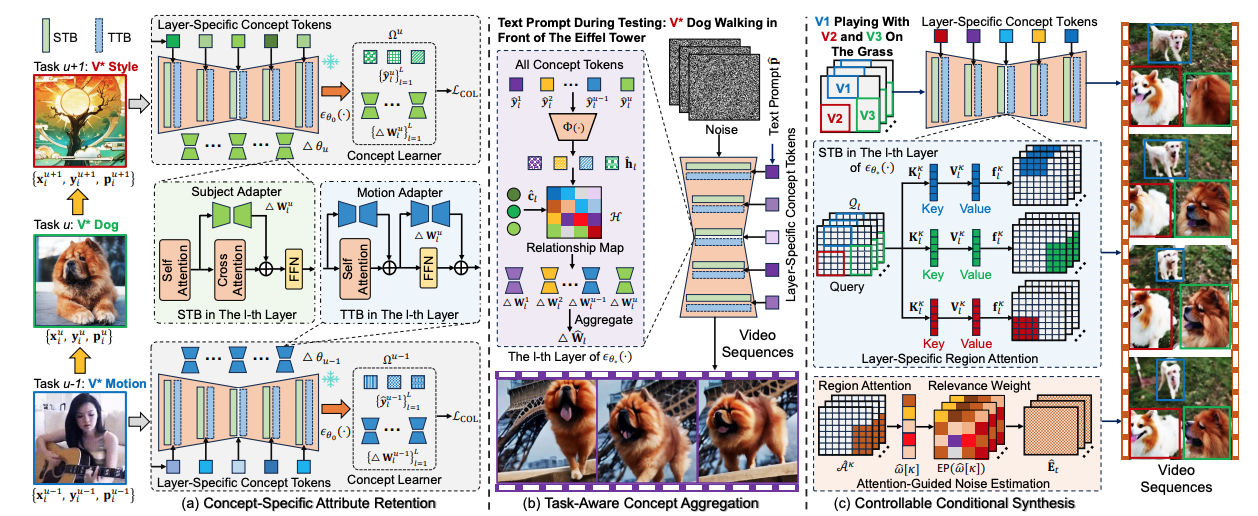
Jiahua Dong*, Xudong Wang*, Wenqi Liang, Zongyan Han, Meng Cao, Duzhen Zhang, Hanbin Zhao, Zhi Han, Salman Khan, Fahad Shahbaz Khan AAAI2026 Paper / Code DetailsCustomized text-to-video generation (CTVG) has recently witnessed significant progress in generating tailored videos from user-specific text. However, existing CTVG methods unrealistically assume that personalized concepts remain static and do not expand incrementally over time. Additionally, they struggle with catastrophic forgetting and concept neglect when continuously learning new concepts, including subjects and motions. To resolve the above challenges, we develop a novel Continual Customized Video Diffusion (CCVD) model, which can continuously learn new concepts to generate videos across various text-to-video generation tasks by tackling catastrophic forgetting and concept neglect. Specifically, to address catastrophic forgetting, we introduce a concept-specific attribute retention module and a task-aware concept aggregation strategy. They can capture the unique characteristics and identities of old concepts during training, while combining all subject and motion adapters of old concepts based on their relevance during testing. Furthermore, to tackle concept neglect, we develop a controllable conditional synthesis to enhance regional features and align video contexts with user conditions, by incorporating layer-specific region attention and attention-guided noise estimation. Experimental comparisons demonstrate that our CCVD model outperforms existing CTVG models. |
|
Junhao Zheng*, Chengming Shi*, Xidi Cai*, Qiuke Li*, Duzhen Zhang, Chenxing Li, Dong Yu, Qianli Ma# IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI2025) Paper / Code DetailsLifelong learning, also known as continual or incremental learning, is a crucial component for advancing Artificial General Intelligence (AGI) by enabling systems to continuously adapt in dynamic environments. While large language models (LLMs) have demonstrated impressive capabilities in natural language processing, existing LLM agents are typically designed for static systems and lack the ability to adapt over time in response to new challenges. This survey is the first to systematically summarize the potential techniques for incorporating lifelong learning into LLM-based agents. We categorize the core components of these agents into three modules: the perception module for multimodal input integration, the memory module for storing and retrieving evolving knowledge, and the action module for grounded interactions with the dynamic environment. We highlight how these pillars collectively enable continuous adaptation, mitigate catastrophic forgetting, and improve long-term performance. This survey provides a roadmap for researchers and practitioners working to develop lifelong learning capabilities in LLM agents, offering insights into emerging trends, evaluation metrics, and application scenarios. |
|
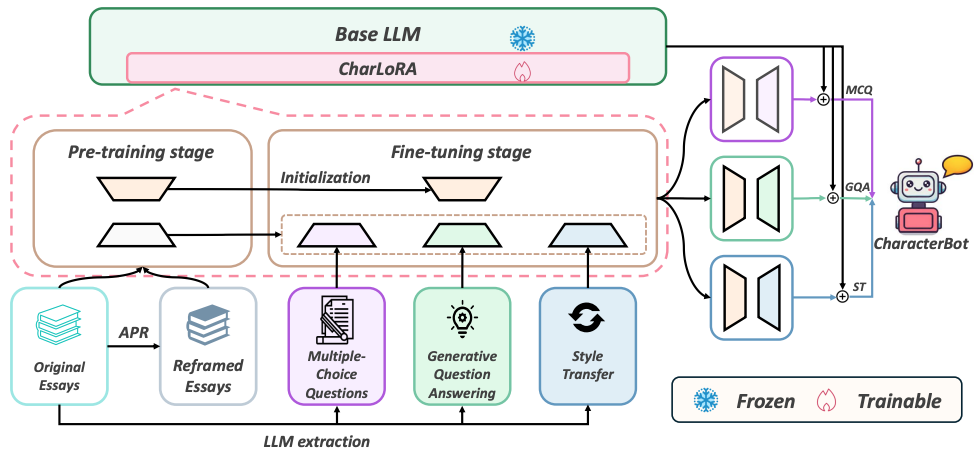
Zixiao Wang, Duzhen Zhang, Ishita Agarwal, Shen Gao, Le Song, Xiuying Chen# ACL2025 findings Paper / Code DetailsPrevious approaches to persona simulation large language models (LLMs) have typically relied on learning basic biographical information, or using limited role-play dialogue datasets to capture a character's responses. However, a holistic representation of an individual goes beyond surface-level facts or conversations to deeper thoughts and thinking. In this work, we introduce CharacterBot, a model designed to replicate both the linguistic patterns and distinctive thought processes of a character. Using Lu Xun, a renowned Chinese writer, as a case study, we propose four training tasks derived from his 17 essay collections. These include a pre-training task focused on mastering external linguistic structures and knowledge, as well as three fine-tuning tasks: multiple-choice question answering, generative question answering, and style transfer, each aligning the LLM with Lu Xun's internal ideation and writing style. To optimize learning across these tasks, we introduce a CharLoRA parameter updating mechanism, where a general linguistic style expert collaborates with other task-specific experts to better study both the language style and the understanding of deeper thoughts. We evaluate CharacterBot on three tasks for linguistic accuracy and opinion comprehension, demonstrating that it significantly outperforms the baselines on our adapted metrics. We hope that this work inspires future research on deep character persona simulation LLM. |
|
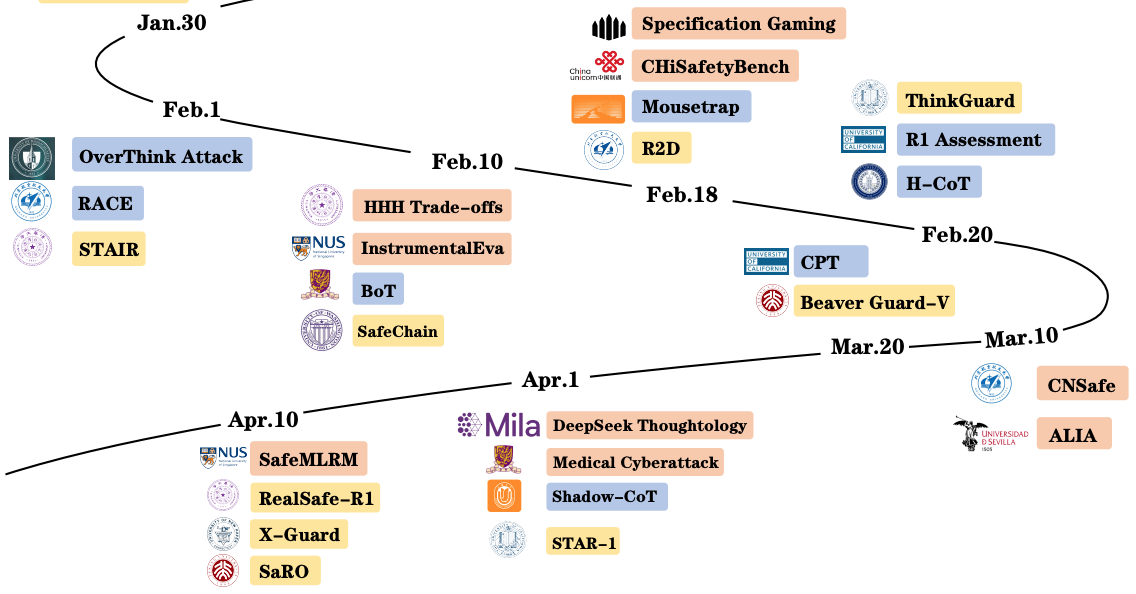
Cheng Wang*, Yue Liu*, Baolong Bi, Duzhen Zhang, Zhong-Zhi Li, YINGWEI MA, Yufei He, Shengju Yu, Xinfeng Li, Junfeng Fang#, Jiaheng Zhang, Bryan Hooi EMNLP2025 findings Paper / Code DetailsLarge Reasoning Models (LRMs) have exhibited extraordinary prowess in tasks like mathematics and coding, leveraging their advanced reasoning capabilities. Nevertheless, as these capabilities progress, significant concerns regarding their vulnerabilities and safety have arisen, which can pose challenges to their deployment and application in real-world settings. This paper presents a comprehensive survey of LRMs, meticulously exploring and summarizing the newly emerged safety risks, attacks, and defense strategies. By organizing these elements into a detailed taxonomy, this work aims to offer a clear and structured understanding of the current safety landscape of LRMs, facilitating future research and development to enhance the security and reliability of these powerful models. |
|
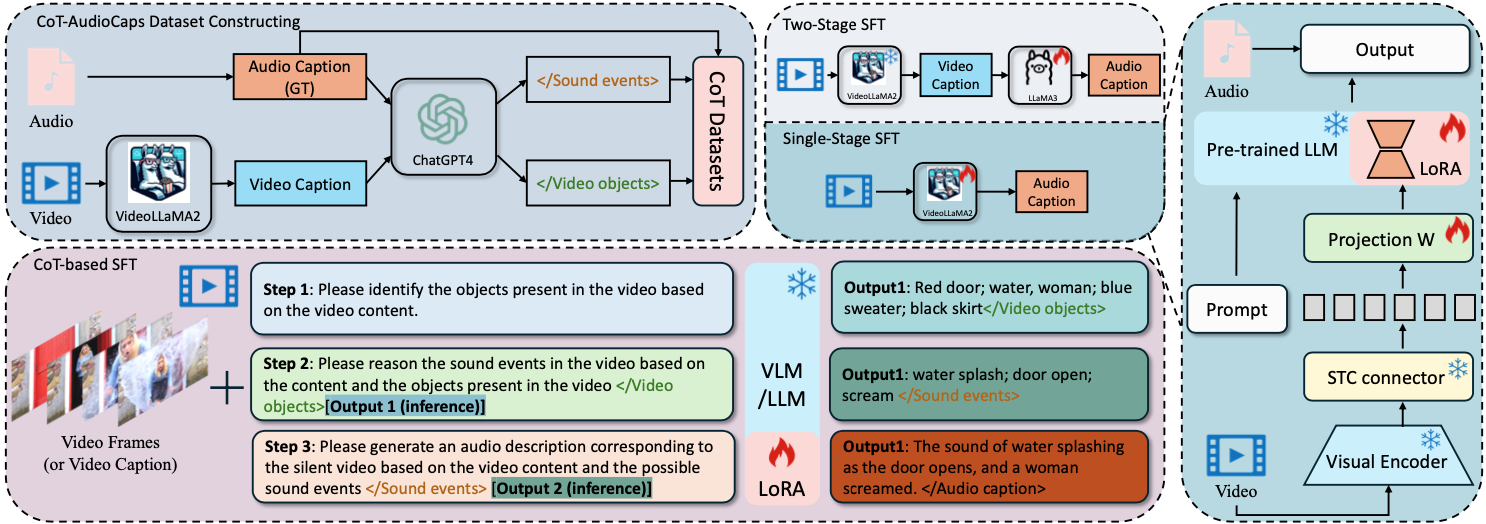
Yong Ren, Chenxing Li#, Le Xu, Hao Gu, Duzhen Zhang, Yujie Chen, Manjie Xu, Ruibo Fu, Shan Yang, Dong Yu# Interspeech2025 Paper DetailsHumans can intuitively infer sounds from silent videos, but whether multimodal large language models can perform modal-mismatch reasoning without accessing target modalities remains relatively unexplored. Current text-assisted-video-to-audio (VT2A) methods excel in video foley tasks but struggle to acquire audio descriptions during inference. We introduce the task of Reasoning Audio Descriptions from Silent Videos (SVAD) to address this challenge and investigate vision-language models' (VLMs) capabilities on this task. To further enhance the VLMs' reasoning capacity for the SVAD task, we construct a CoT-AudioCaps dataset and propose a Chain-of-Thought-based supervised fine-tuning strategy. Experiments on SVAD and subsequent VT2A tasks demonstrate our method's effectiveness in two key aspects: significantly improving VLMs' modal-mismatch reasoning for SVAD and effectively addressing the challenge of acquiring audio descriptions during VT2A inference. |
|
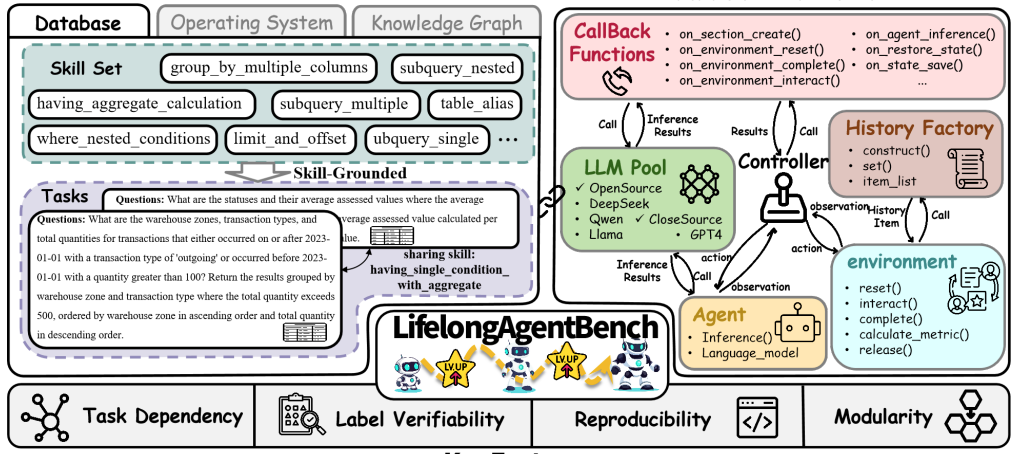
Junhao Zheng*, Xidi Cai*, Qiuke Li, Duzhen Zhang, Zhong-Zhi Li, Yingying Zhang, Le Song, Qianli Ma# Preprint2025 Paper / Code / Dataset DetailsLifelong learning is essential for intelligent agents operating in dynamic environments. Current large language model (LLM)-based agents, however, remain stateless and unable to accumulate or transfer knowledge over time. Existing benchmarks treat agents as static systems and fail to evaluate lifelong learning capabilities. We present LifelongAgentBench, the first unified benchmark designed to systematically assess the lifelong learning ability of LLM agents. It provides skill-grounded, interdependent tasks across three interactive environments, Database, Operating System, and Knowledge Graph, with automatic label verification, reproducibility, and modular extensibility. Extensive experiments reveal that conventional experience replay has limited effectiveness for LLM agents due to irrelevant information and context length constraints. We further introduce a group self-consistency mechanism that significantly improves lifelong learning performance. We hope LifelongAgentBench will advance the development of adaptive, memory-capable LLM agents. |
|
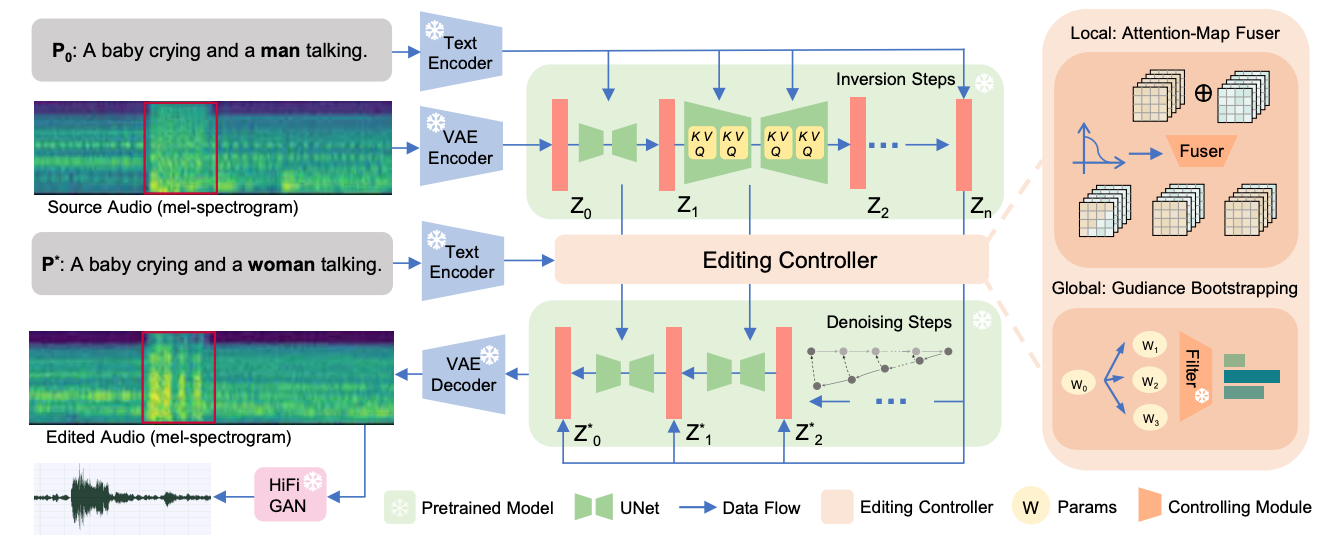
Manjie Xu, Chenxing Li#, Duzhen Zhang, Dan Su, Wei Liang#, Dong Yu# ICML2024 Paper / Project DetailsAudio editing involves the arbitrary manipulation of audio content through precise control. Although text-guided diffusion models have made significant advancements in text-to-audio generation, they still face challenges in finding a flexible and precise way to modify target events within an audio track. We present a novel approach, referred to as PPAE, which serves as a general module for diffusion models and enables precise audio editing. The editing is based on the input textual prompt only and is entirely training-free. We exploit the cross-attention maps of diffusion models to facilitate accurate local editing and employ a hierarchical local-global pipeline to ensure a smoother editing process. Experimental results highlight the effectiveness of our method in various editing tasks. |
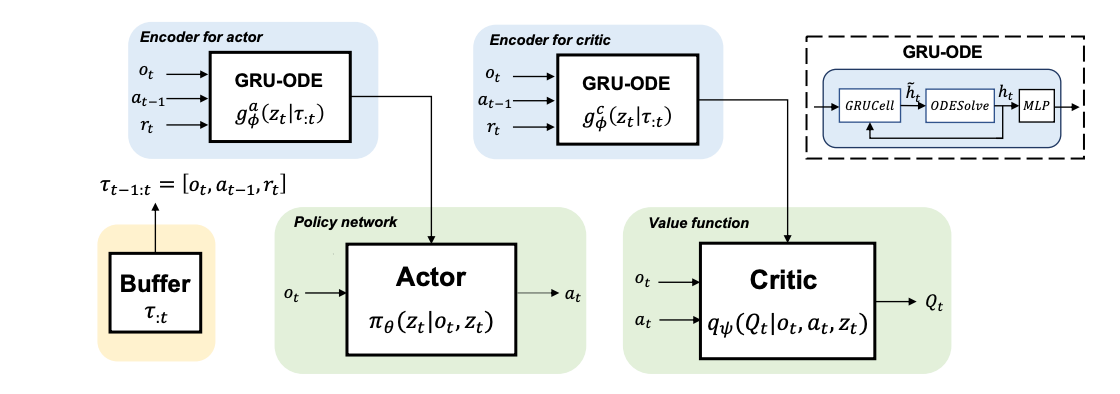
|
Xuanle Zhao, Duzhen Zhang, Liyuan Han, Tielin Zhang#, Bo Xu# NeurIPS2023 Paper DetailsNeural ordinary differential equations (ODEs) are widely recognized as the standard for modeling physical mechanisms, which help to perform approximate inference in unknown physical or biological environments. In partially observable (PO) environments, how to infer unseen information from raw observations puzzled the agents. By using a recurrent policy with a compact context, context-based reinforcement learning provides a flexible way to extract unobservable information from historical transitions. To help the agent extract more dynamics-related information, we present a novel ODE-based recurrent model combines with model-free reinforcement learning (RL) framework to solve partially observable Markov decision processes (POMDPs). We experimentally demonstrate the efficacy of our methods across various PO continuous control and meta-RL tasks. Furthermore, our experiments illustrate that our method is robust against irregular observations, owing to the ability of ODEs to model irregularly-sampled time series. |

|
Qingyu Wang*, Tielin Zhang*#, Minglun Han*, Yi Wang, Duzhen Zhang, Bo Xu# AAAI2023 Paper DetailsThe spiking neural network (SNN) using leaky-integrated-and-fire (LIF) neurons has been commonly used in automatic speech recognition (ASR) tasks. However, the LIF neuron is still relatively simple compared to that in the biological brain. Further research on more types of neurons with different scales of neuronal dynamics is necessary. Here we introduce four types of neuronal dynamics to post-process the sequential patterns generated from the spiking transformer to get the complex dynamic neuron improved spiking transformer neural network (DyTr-SNN). We found that the DyTr-SNN could handle the non-toy automatic speech recognition task well, representing a lower phoneme error rate, lower computational cost, and higher robustness. These results indicate that the further cooperation of SNNs and neural dynamics at the neuron and network scales might have much in store for the future, especially on the ASR tasks. |
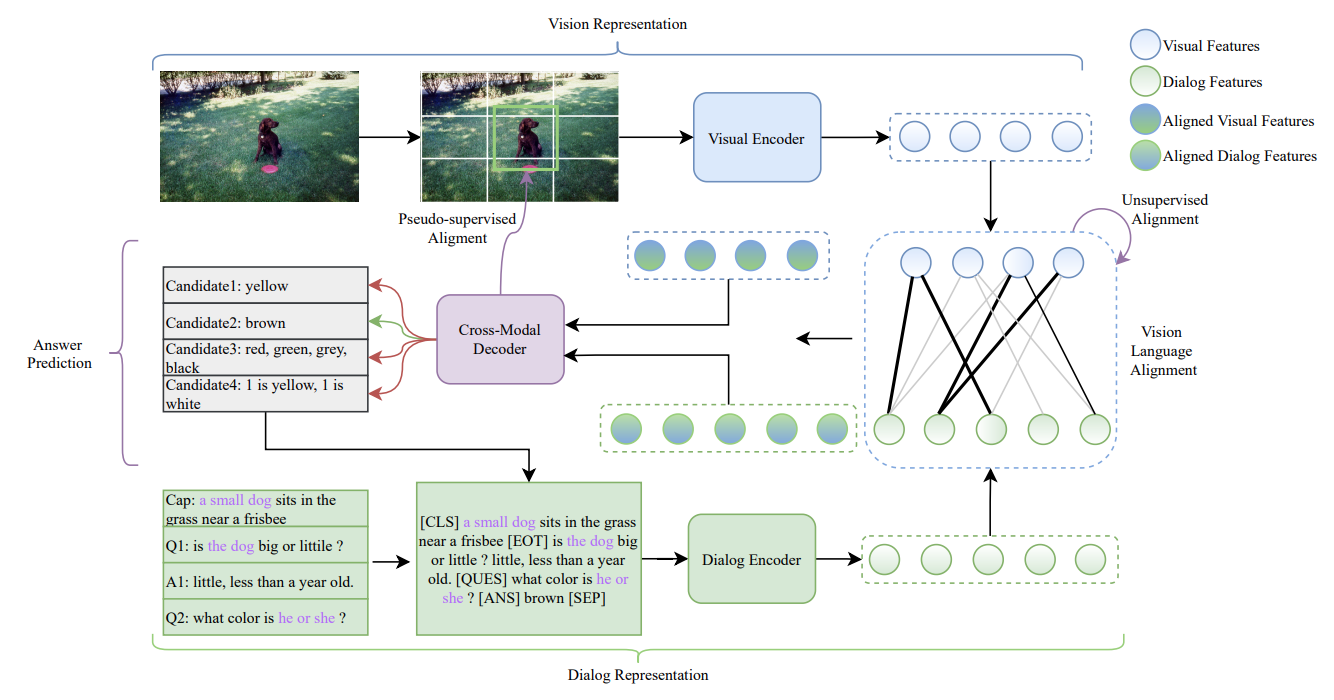
|
Feilong Chen, Duzhen Zhang, Xiuyi Chen#, Jing Shi, Shuang Xu, Bo Xu ACM MM2022 Paper DetailsVisual dialog requires models to give reasonable answers according to a series of coherent questions and related visual concepts in images. However, most current work either focuses on attention-based fusion or pre-training on large-scale image-text pairs, ignoring the critical role of explicit vision-language alignment in visual dialog. To remedy this defect, we propose a novel unsupervised and pseudo-supervised vision-language alignment approach for visual dialog (AlignVD). Firstly, AlginVD utilizes the visual and dialog encoder to represent images and dialogs. Then, it explicitly aligns visual concepts with textual semantics via unsupervised and pseudo-supervised vision-language alignment (UVLA and PVLA). Specifically, UVLA utilizes a graph autoencoder, while PVLA uses dialog-guided visual grounding to conduct alignment. Finally, based on the aligned visual and textual representations, AlignVD gives a reasonable answer to the question via the cross-modal decoder. Extensive experiments on two large-scale visual dialog datasets have demonstrated the effectiveness of vision-language alignment, and our proposed AlignVD achieves new state-of-the-art results. In addition, our single model has won first place on the visual dialog challenge leaderboard with a NDCG metric of 78.70, surpassing the previous best ensemble model by about 1 point. |
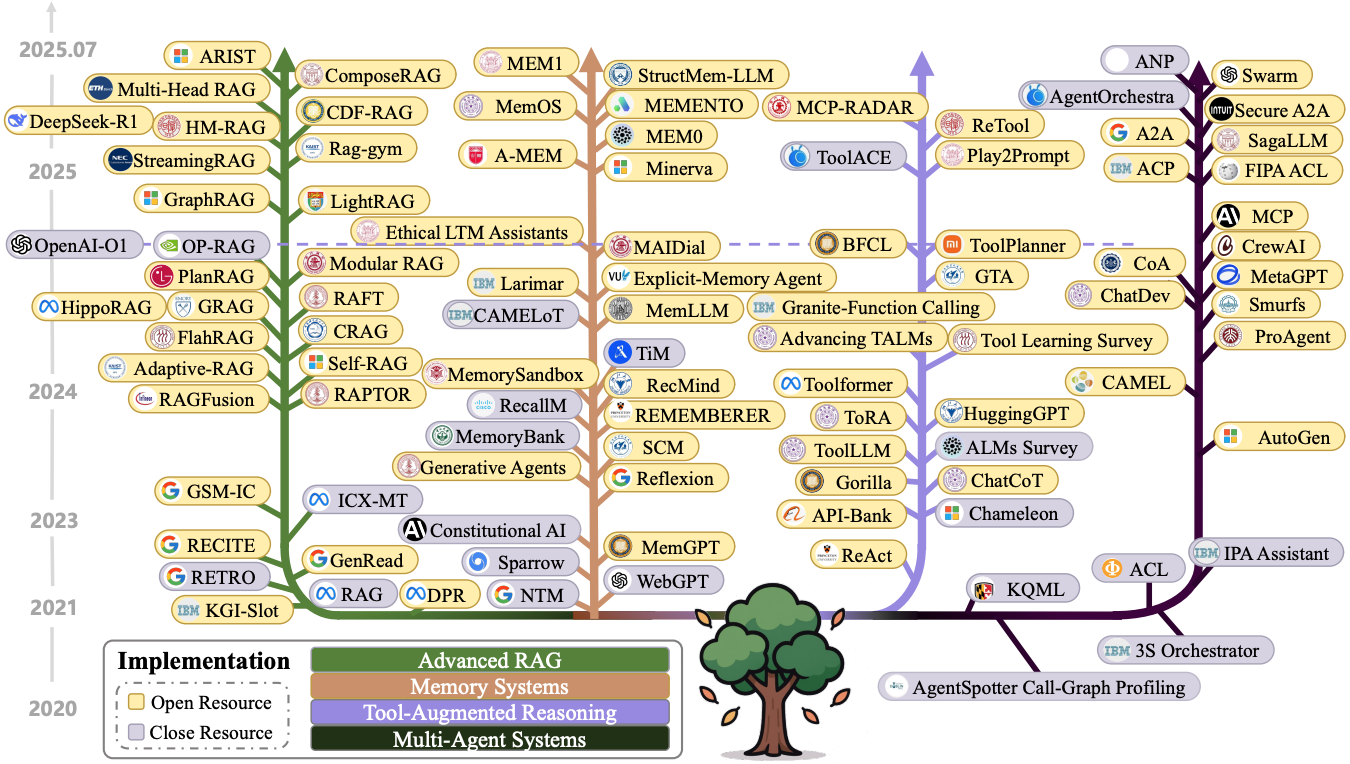
|
Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, Chenlin Zhou, Jiayi Mao, Tianze Xia, Jiafeng Guo, Shenghua Liu# Preprint 2025 Paper / Code DetailsThe performance of Large Language Models (LLMs) is fundamentally determined by the contextual information provided during inference. This survey introduces Context Engineering, a formal discipline that transcends simple prompt design to encompass the systematic optimization of information payloads for LLMs. We present a comprehensive taxonomy decomposing Context Engineering into its foundational components and the sophisticated implementations that integrate them into intelligent systems. We first examine the foundational components: context retrieval and generation, context processing and context management. We then explore how these components are architecturally integrated to create sophisticated system implementations: retrieval-augmented generation (RAG), memory systems and tool-integrated reasoning, and multi-agent systems. Through this systematic analysis of over 1300 research papers, our survey not only establishes a technical roadmap for the field but also reveals a critical research gap: a fundamental asymmetry exists between model capabilities. While current models, augmented by advanced context engineering, demonstrate remarkable proficiency in understanding complex contexts, they exhibit pronounced limitations in generating equally sophisticated, long-form outputs. Addressing this gap is a defining priority for future research. Ultimately, this survey provides a unified framework for both researchers and engineers advancing context-aware AI. |

|
Qingyu Wang, Duzhen Zhang, Tielin Zhang#, Bo Xu# Frontiers in Neuroscience 2024 Paper DetailsEnergy-efficient spikformer has been proposed by integrating the biologically plausible spiking neural network (SNN) and artificial transformer, whereby the spiking self-attention (SSA) is used to achieve both higher accuracy and lower computational cost. However, it seems that self-attention is not always necessary, especially in sparse spike-form calculation manners. In this article, we innovatively replace vanilla SSA (using dynamic bases calculating from Query and Key) with spike-form Fourier transform, wavelet transform, and their combinations (using fixed triangular or wavelets bases), based on a key hypothesis that both of them use a set of basis functions for information transformation. Hence, the Fourier-or-Wavelet-based spikformer (FWformer) is proposed and verified in visual classification tasks, including both static image and event-based video datasets. The FWformer can achieve comparable or even higher accuracies (0.4%–1.5%), higher running speed (9%–51% for training and 19%–70% for inference), reduced theoretical energy consumption (20%–25%), and reduced graphic processing unit (GPU) memory usage (4%–26%), compared to the standard spikformer. Our result indicates the continuous refinement of new transformers that are inspired either by biological discovery (spike-form), or information theory (Fourier or Wavelet transform), is promising. |
|
Outstanding Area Chairs: ARR2025 Oct.(EACL2026) Conference Area Chairs: ARR2025 Oct.(EACL2026), ARR2026 Jan.(ACL2026), ARR2026 May(EMNLP2026), ARR2026 Aug.(NAACL2027), AAAI2027 Conference Reviewers: AAAI2023-2024,2026, ACL2023-2025, IJCAI2023-2024, EMNLP2023-2025, CVPR2024-2026, NAACL2025, ICCV2025, NeurIPS2025, ICLR2026, ECCV2026, ICML2026, ACM MM2026 Journal Reviewers: Npj Digital Medicine, IEEE TPAMI, IEEE TASLP, IEEE TMM |
Website template
Last updated: Aug. 2026